[간단 설명] 기본적인 CNN 아키텍처 설명 | VGGNet, ResNet, Densenet
- VGGNet - Very Deep Convolutional Networks for Large-Scale Image Recognition / arXiv 2014
- ResNet - Deep Residual Learning for Image Recognition / CVPR 2016
- Densenet - Densely Connected Convolutional Networks / CVPR 2017
VGGNet
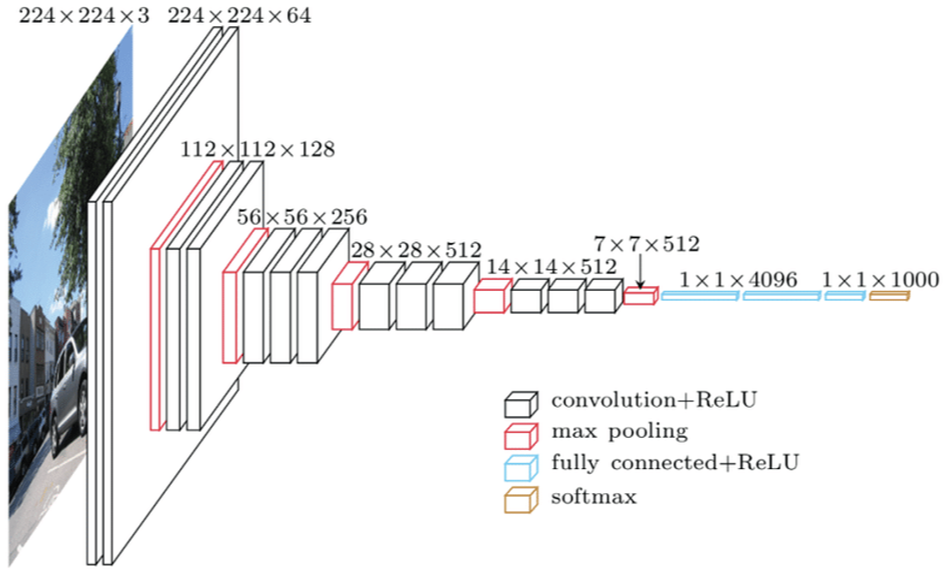
VGGNet은 AlexNet보다 network의 layer가 2배이상 깊어지며 더욱 복잡한 task를 해결할 수 있습니다. Network layer 가 깊어지고 성능이 향상될 수 있었던 이유는 VGGNet부터 convolutional filter를 3x3 size를 사용하여 네트워크를 깊게 쌓기 시작했기 때문입니다.
큰 사이즈의 conv. filter를 하나 사용하는 것보다 작은 사이즈의 filter를 여러개 사용하면 activation function을 더 많이 사용할 수 있어서, 네트워크의 non-linearity(비선형성)는 증가시키고, parameter 수는 감소시켜주기 때문입니다.
이전 네트워크에 비해 성능이 증가하긴 했지만, 마지막 conv. layer의 output feature map을 flatten 시킨 후 FC layer에 넣어주는 방식이기 때문에, FC layer parameter 수가 너무 많고 intput image 사이즈가 고정되어야한다는 것이 매우 큰 단점이고, GAP를 사용하지 않기 때문에 input 이미지의 각 픽셀들의 spatial order에 민감에 질 수 있는 네트워크 입니다.
Network의 nonlinearity는 conv filter 뒤에 연결되는 non-linear function(e.g. ReLU, Sigmoid,...)이 많아질 수록 증가하며, nonlinearity가 증가할 수록 더욱 섬세하게 decision boundary 를 정할 수 있으므로 task가 복잡해질 수록 non-linearity가 중요합니다.
* 2022년 기준으로 VGGNet으로 backbone으로 evaluation을 하는 연구는 거의 없습니다.
ResNet
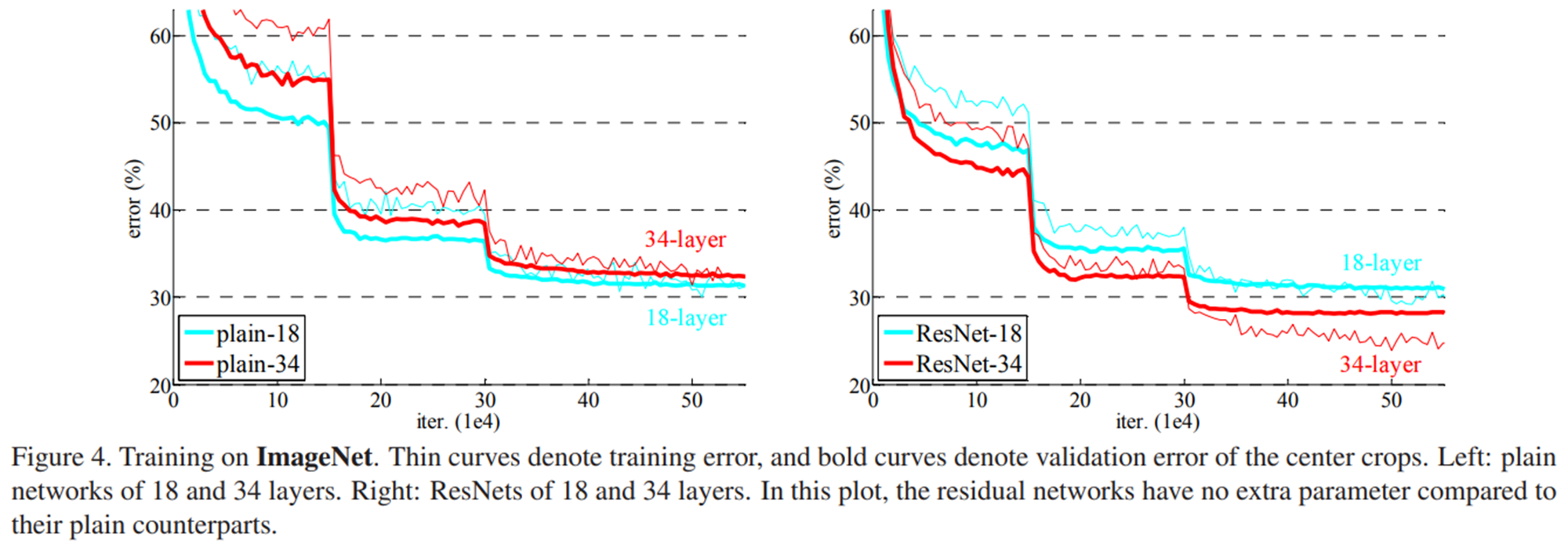
VGGNet이 layer를 깊게 만들면서 성능을 증가시켰지만, layer가 더 많이 깊어질 때는 성능 증가가 미미합니다. 이는 이때까지 사용되던 deep neural network의 layer가 깊어지면 gradient vanishing/exploding 등의 이유로 training이 잘 되지 않기 때문입니다.
위 그림의 왼쪽 표를 보면 plain-34 가 더 깊은 network임에도 불구하고 오히려 test error 가 높은 것을 확인할 수 있습니다.

ResNet은 이를 해결하기 위해 위 그림와 같은 residual learning(skip connection으로 구현)을 사용합니다. Residual learning은 우리말로는 '잔차 학습' 으로 어떤 값의 차이(잔차)를 학습한다는 의미입니다. 기존의 네트워크에서 F(x) = H(x)를 학습할 때(F는 현재 layer의 embedding function입니다), residual learning으로 F(x) = H(x) - x (잔차)를 학습하려 하는 것입니다. 이러한 residual learning을 위해서 H(x) = F(x) + x 가 되어야 하므로 skip connection(shortcut)으로 weight layer 이전의 입력(x)와 weight layer를 통과한 F(x)를 더해줍니다.
이는 network를 training 할 때 optimal한 H(x)를 찾는 것에서 optimal한 F(x)=H(x)-x(출력과 입력의 차) 를 찾는 방향으로 학습하게 변경된 것이며, 이러한 residual mapping이 gradient vanishing/exploding을 막아주고 기존의 CNN보다 optimize가 잘 되어서 network의 layer가 깊어지더라도 학습이 잘 되게 합니다.
조금 더 살펴보면, F(x)=H(x)-x를 최소화하면 0=H(x)-x가 되고(ideal한 상황) H(x)=x가 되므로, H(x)를 x로 mapping하는 것이 학습의 목표가 됩니다. 어떤 값으로 최적화해야할지 모르는 H(x) 가 H(x)=x 라는 최적화의 목표값이 제공되기 때문에 identity mapping인 F(x)가 학습이 더 쉬워집니다.
또한, 곱셈 연산에서 덧셈 연산으로 변형되는데, 아래식 (1), (2)는 residual unit을 수식으로 나타낸 것입니다.
F = residual function
f = activation function
h = identity mapping function(3x3 conv)
activation function f를 identity mapping이라고 생각하면 x_(l+1)=y_l 이므로 (3)번식이 성립되고 이를 반복적으로 대입하면 (4)번 수식이 만들어 집니다.
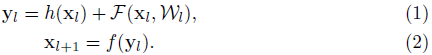


L은 전체 layer의 인덱스이고, l은 layer 하나하나를 나타냅니다. (4)번 식을 보면 residual unit을 사용하면 forward 시에 전체 네트워크 연산을 residual function인 F들의 합으로 표현할 수 있고, 양변을 미분하면 (5)번 식이 됩니다. 괄호 안의 우변이 배치마다 항상 -1이 되는 경우는 거의 없기 때문에 vanishing이 발생할 확률이 매우 적어집니다.
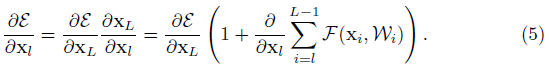
결론적으로, residual learning을 사용하면 shortcut을 통해 네트워크 연산이 곱셈이 아닌 덧셈들로 이루어지기 때문에 정보의 전달이 쉽고 weight 이 연속된 곱셈들로 전달되는 것이 아니기 때문에 vanishing이 발생하지 않습니다. 때문에 residual learning을 사용하면 네트워크가 깊이에 대한 한계를 벗어날 수 있습니다.
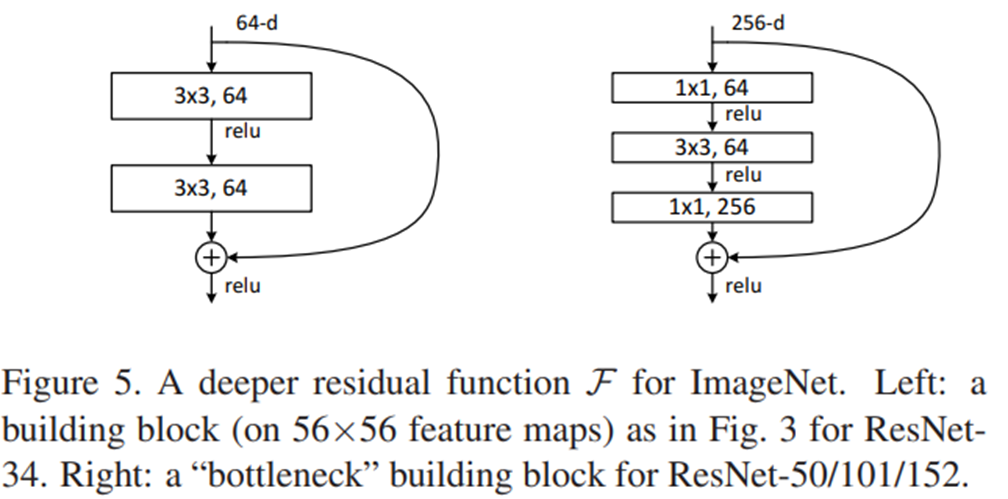
또한, ResNet-50 이상의 모델에서는 parameter 수가 점점 많아지면서, bottleneck 구조를 차용하여 bottleneck residual block 을 중첩하여 사용합니다.
*Bottleneck residual : "1x1 conv(채널 감소) → 3x3 conv → 1x1 conv(채널 증가)" 구조를 사용하며 채널을 줄인 상태에서 conv. 연산을 하고 다시 채널 수를 원래대로 바꿔서 short cut 연산을 수행
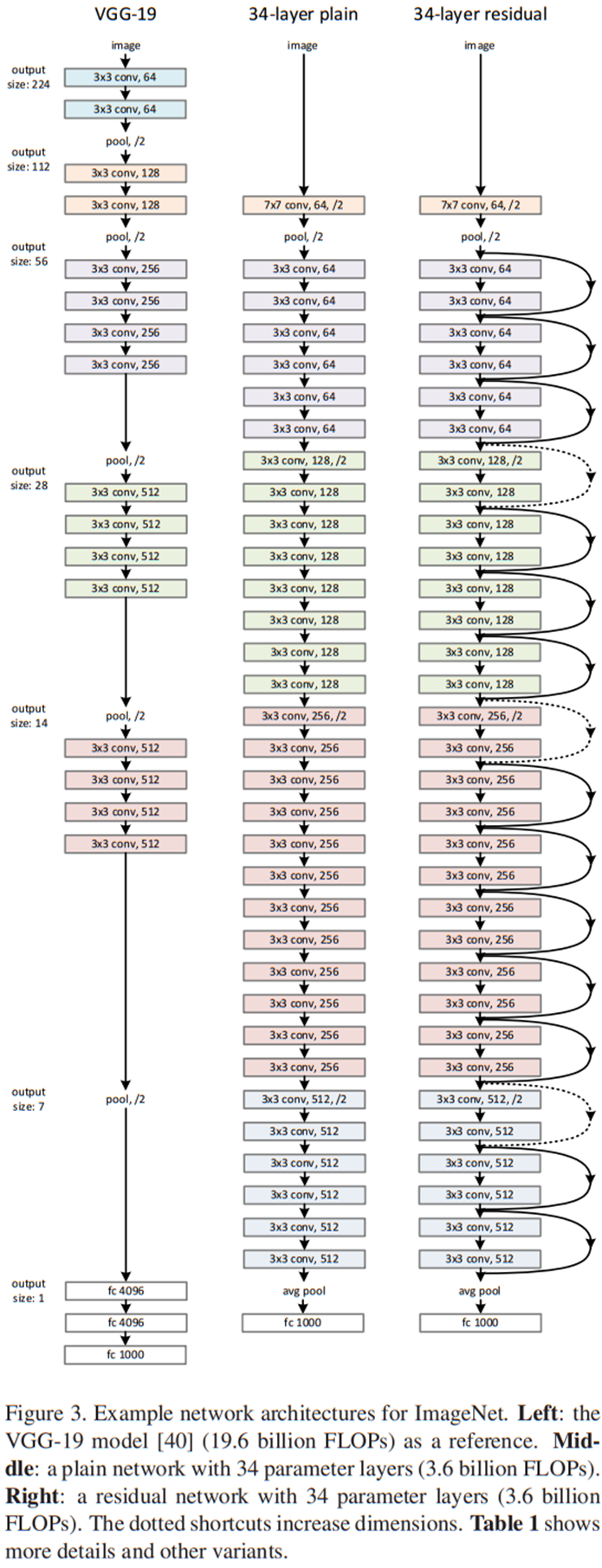
위 그림처럼 plain network에 단순히 skip connection 을 추가해준 것이 residual learning 방식이며, residual learning 방식을 적용하면 layer가 깊어질수록 성능이 좋아지는 것을 확인할 수 있습니다.
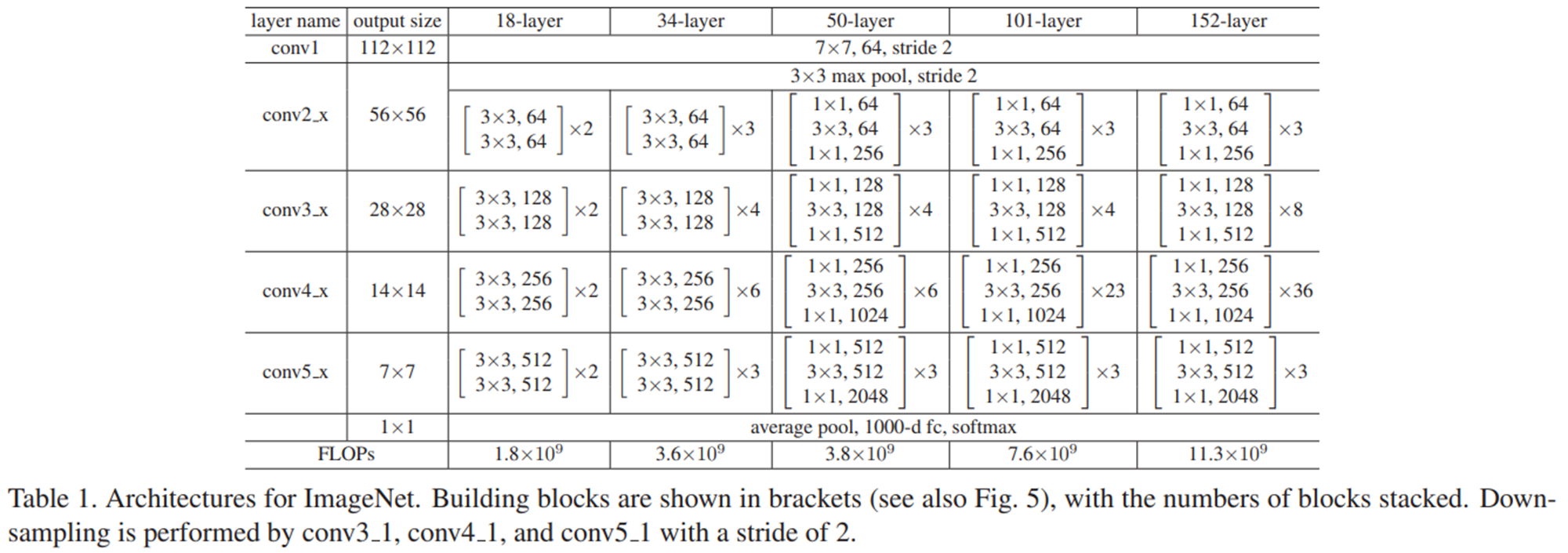
위 표는 ResNet18 ~ ResNet152 architecture이며 input 이미지 사이즈가 224x224 일때 각 layer output의 spatial size와 channel size 를 확인할 수 있습니다. 각 사이즈별 network는 pytorch에서 ImageNet으로 pre-train 된 모델을 제공하고 있어서 여러 task에 활용할 수 있습니다.
ResNet은 거의 대부분의 vision task(e.g. classification, segmentation, depth estimation, 3D vision, etc,...)에서 backbone network로 활용되고 있으므로, 구조를 면밀히 이해해보는 것이 중요합니다. 이미 vanilla resnet 보다 더 좋은 성능을 내는 network와 learning method 들이 많이 있지만, 대부분의 분야에서 새로운 method의 성능 비교를 위해 동일한 조건(동일 dataset, 동일 backbone 또는 유사한 parameter 수/계산량의 network)에서 evalutation을 하기 때문입니다.
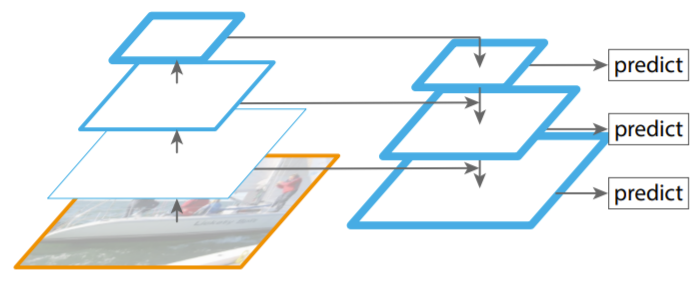
예를 들어, object detection과 segmentation에 사용되는 위의 FPN(Feature Pyramid Network) 구조에서 좌측 encoder output이 우측 decoder input으로 연결되는데, encoder의 각 output은 resnet의 각 residual block(conv2_x, conv3_x, conv4_x, conv5_x)의 output 입니다.
이렇듯 backbone net으로 resnet이 많이 사용되기 때문에, 특정 연구분야에서 새로운 network를 제안하려 할 때, resnet에서 발전시키는 경우가 많습니다.
@ Pytorch 코드 예시
- pytorch 에서 제공되는 ImageNet pre-train된 resnet을 불러와서, forward 함수에서 각 residual block의 output을 따로 저장하여 여러 vision task에 활용할 수 있습니다.
class Resnet_application(nn.Module):
def __init__(self,nclass):
super(Resnet_application, self).__init__()
self.resnet = models.resnet50(pretrained=True)
self.resnet.fc = nn.Linear(2048,nclass)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
def forward(self, x):
conv_out = []
x = self.resnet.conv1(x)
x = self.resnet.bn1(x)
x = self.resnet.relu(x)
x = self.resnet.maxpool(x)
x = self.resnet.layer1(x); conv_out.append(x);
x = self.resnet.layer2(x); conv_out.append(x);
x = self.resnet.layer3(x); conv_out.append(x);
x = self.resnet.layer4(x); conv_out.append(x);
x = self.avgpool(x)
x = x.reshape(x.size(0),x.size(1))
x = self.resnet.fc(x); conv_out.append(x);
return conv_out
if __name__ == "__main__":
model = Resnet_application(100).cuda()
x = torch.rand((1,3,224,224)).cuda()
y = model(x)
print(y[0].shape,y[1].shape,y[2].shape,y[3].shape,y[4].shape)torch.Size([1, 256, 56, 56]) torch.Size([1, 512, 28, 28]) torch.Size([1, 1024, 14, 14]) torch.Size([1, 2048, 7, 7]) torch.Size([1, 100])
DenseNet
Densenet은 모든 layer의 feature map을 concatenation 하는 Dense Block으로 구성된 deep neual network 입니다. Resnet과 비교하면, resnet은 skip connection에서 elemenet-wise 덧셈을 이용하고 densenet 은 channel 축으로 concat 하는 방식을 이용합니다.
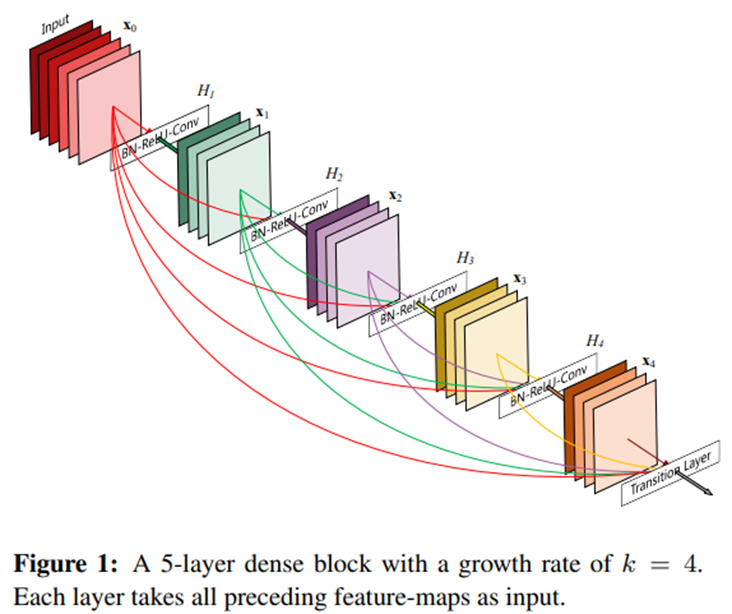
다만, 채널을 계속 concat 하면 채널 수가 너무 많아지기 때문에, 각 layer feature map의 채널 개수를 작은 수의 growth rate(k)로 사용합니다. Figure 1에서 k=4(hyper param.) 인 경우이며, 그림 기준으로 6 channel feature input이 dense block 4개를 통과하면 6 + 4 + 4 + 4 + 4 =22 개의 channel을 가지게 됩니다.
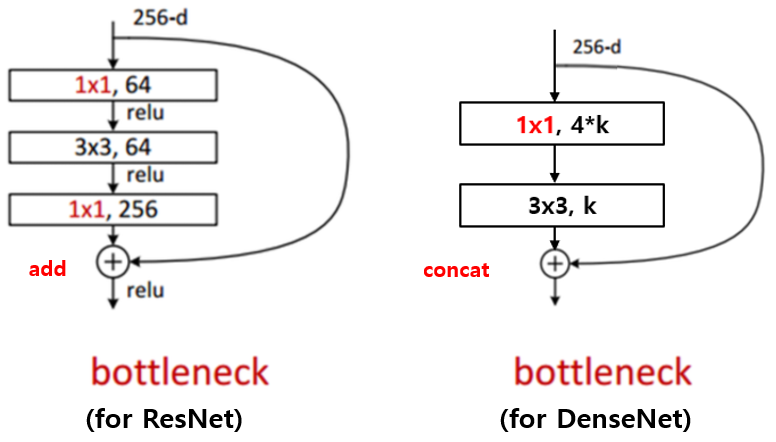
Bottleneck의 경우, resnet은 "1x1 conv → 3x3 conv → 1x1 conv" 의 구조이지만, densenet에서는 "1x1 conv → 3x3 conv" 만 사용합니다. 다만 1x1 conv 로 채널 개수를 4*k 개로 줄이고 3x3 conv로 다시 k개의 채널로 줄이는 방식을 사용합니다.
Dense Block 사이 사이에는 Transition layer가 존재하는데, 이는 "1x1 conv + average pooling"을 수행하여 feature map의 spatial size와 chanel 수를 줄이는 역할을 합니다. 이 때 1x1 conv 로 channel 수를 줄이는 비율은 theta=0.5 를 사용합니다.

Densenet의 전체적인 구조는 위와 같으며, Dense Block + Transition layer 의 반복으로 구성되어 있습니다.
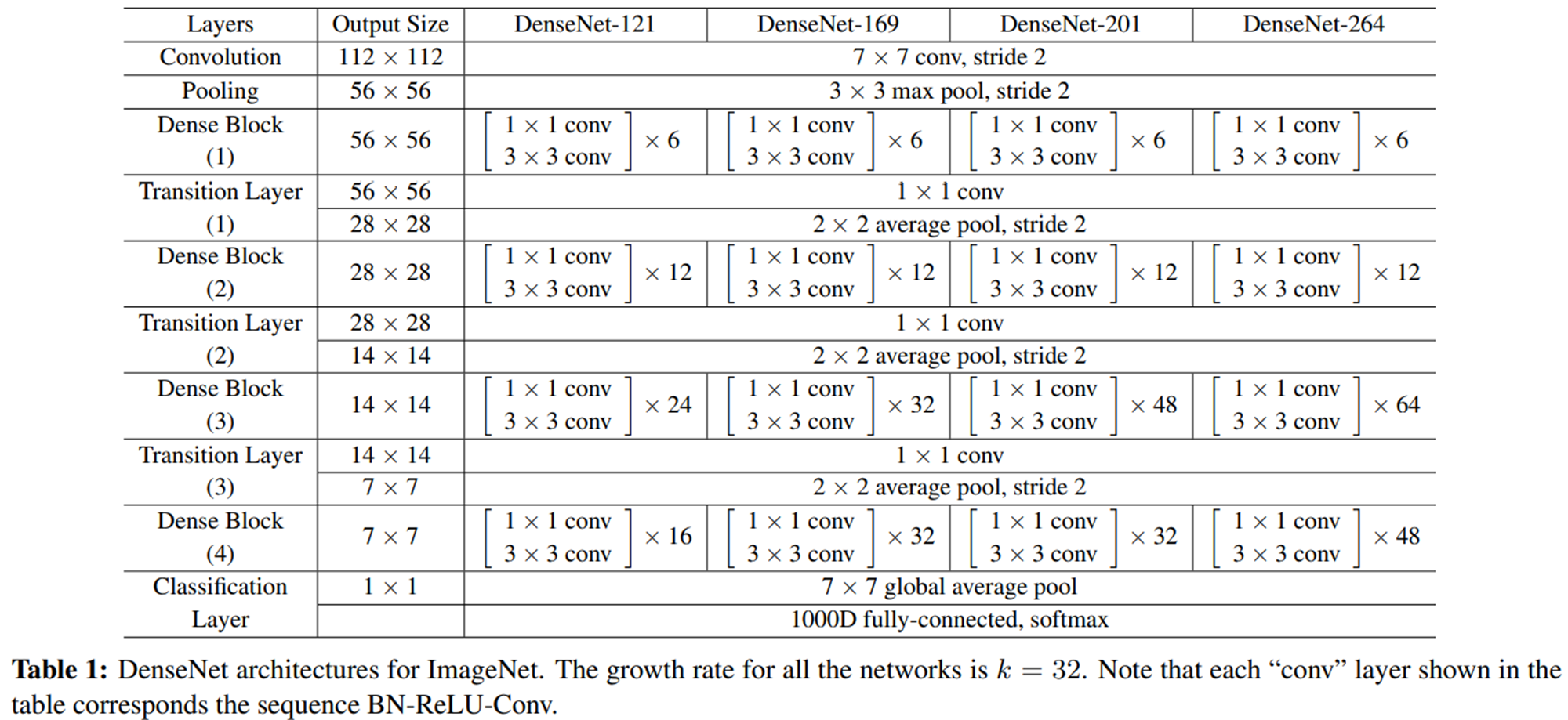
정리하면, Densenet은 channel 축 concatenation 방식으로 skip connection을 하는 dense block 를 깊게 쌓은 network로 나머지 구조는 feature map 이 너무 커지지 않도록(효율적인 연산을 위해) 조절해주는 역할을 합니다.
resnet, densenet 은 여러 vision task 연구에서 backbone network로 많이 사용되고, 해당 논문들은 image feature에 대한 이해도를 높여주는 좋은 논문이기에 꼭 읽어보면 좋을 것 같습니다 !