https://arxiv.org/abs/2503.19786
1. Introduction
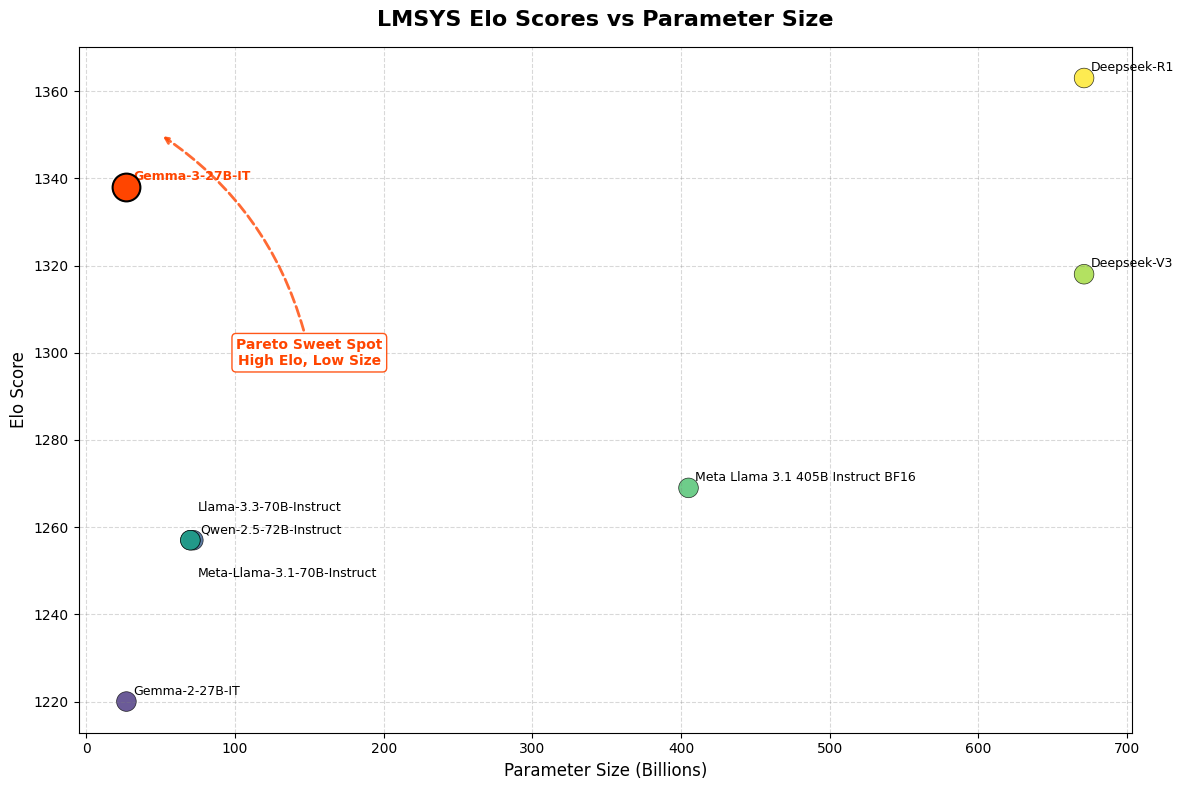
Gemma 3는 Google DeepMind가 2025년 3월 공개한 경량 오픈 모델 시리즈에 멀티모달 비전 능력을 추가한 모델이다. Pan and Scan (P&S) 방법으로 유연한 이미지 해상도를 지원하며, Local/Global Attention 혼합 구조로 128K 토큰 컨텍스트를 효율적으로 처리한다.
Google Gemma 시리즈는 오픈소스 경량 LLM으로 출발했다. Gemma 2까지는 텍스트 전용 모델이었지만, 실제 응용에서는 이미지와 텍스트를 함께 처리하는 능력이 필요하기에 MLLM으로 발전했다.
경량 model에 멀티모달 능력을 추가할 때의 주요 과제는 메모리 효율성이다. Vision encoder는 많은 token을 생성하며, 긴 context를 처리하려면 KV-cache 메모리가 급격히 증가한다. 예를 들어, 128K token context를 처리하려면 KV-cache만으로도 수 GB의 메모리가 필요하다. Gemma 3는 이 문제를 Local/Global Attention 혼합 구조로 해결했다.
2. Technical Approach
Gemma 3는 경량 model에 멀티모달 능력을 효율적으로 추가하기 위해 몇 가지 핵심 설계를 채택했다.
2.1. SigLIP Vision Encoder
SigLIP Vision Encoder는 이미지를 256개의 고정된 soft token으로 encoding한다. 이는 메모리 효율성을 보장하면서도 충분한 시각 정보를 전달하는 핵심 설계다.
핵심 아이디어
- 고정된 token 수(256개)로 메모리 사용 예측 가능
- Contrastive learning으로 학습된 vision encoder
- 이미지-텍스트 정렬에 효과적
세부사항
- 이미지 정규화: 896x896 resolution으로 정규화
- Token 수 제한: 256개의 고정된 soft token
- 메모리 효율성: 제한된 token 수로 메모리 사용 최소화
- 정보 보존: 충분한 시각 정보 전달
SigLIP Vision Encoder는 고정된 token 수로 메모리 사용량을 예측 가능하게 하여 경량 model에 적합한 설계다. 256개의 soft token으로 제한하면서도 이미지-텍스트 정렬 성능이 우수하여, 메모리 효율성과 성능의 균형을 잘 달성한다.
2.2. Pan and Scan (P&S)
Pan and Scan (P&S) 방법은 LLaVA에서 영감을 받아 유연한 이미지 resolution을 지원한다. 고정된 resolution 대신 다양한 종횡비의 이미지를 효율적으로 처리할 수 있게 해준다.
Pan and Scan은 고해상도나 비정사각형 이미지를 고정된 resolution으로 리사이즈하는 대신, adaptive windowing 알고리즘을 통해 이미지를 여러 개의 겹치지 않는 crop으로 분할한다. 각 crop은 원본 이미지의 aspect ratio를 유지한 채로 독립적으로 vision encoder에 의해 처리되며, 이후 language model에서 통합된다. 이 방식은 이미지를 강제로 정사각형으로 변형하거나 해상도를 낮추지 않아도 되므로, 왜곡 없이 다양한 종횡비의 이미지를 효율적으로 처리할 수 있다. 예를 들어, 가로로 긴 파노라마 이미지나 세로로 긴 포스터 이미지도 원본 비율을 유지하면서 여러 개의 crop으로 나누어 처리할 수 있다.
핵심 아이디어
- 실제 응용에서는 다양한 크기와 비율의 이미지가 입력됨
- 고정된 resolution은 이미지 왜곡이나 정보 손실 발생 가능
- 유연한 resolution 처리로 다양한 이미지 효율적 처리
세부사항
- 종횡비 유지: 원본 이미지의 종횡비 보존
- 효율적 처리: 다양한 크기의 이미지를 효율적으로 처리
- 정보 손실 최소화: 이미지 왜곡 최소화
2.3. Local/Global Attention

Local/Global Attention 혼합 구조는 긴 컨텍스트를 처리하면서도 KV-cache 메모리 증가를 관리하기 위한 핵심 설계다. 이는 경량 모델에서 긴 컨텍스트를 지원하는 혁신적인 방법이다.
핵심 아이디어
- 긴 컨텍스트를 처리하려면 KV-cache 메모리가 급격히 증가
- 모든 토큰에 대해 global attention을 수행하면 메모리 부족
- Local attention과 Global attention을 혼합하여 효율성과 성능 균형
세부사항
- Local Attention Layer:
- 1024 token 범위에서 작동
- 근처 token만 참조하여 메모리 사용 제한적
- 빠른 계산 가능
- Global Attention Layer:
- 전체 시퀀스에 attention 수행
- 전체 맥락 유지
- 5개의 local layer마다 1개의 global layer 배치 (5:1 비율)
- 혼합 구조:
- Local layer: 빠른 처리, 제한된 메모리
- Global layer: 전체 맥락 유지
- 두 가지를 적절히 혼합하여 효율성과 성능 확보
Local/Global Attention 혼합 구조는 128K token context를 지원하면서도 KV-cache 메모리 증가를 크게 제한한다. 모든 layer에서 full attention을 수행하는 경우와 비교하면, local layer는 1024 token window만 사용하므로 KV cache 메모리 사용량이 크게 감소한다. Global layer는 전체 128K token에 attention하지만 전체 layer의 약 1/6(5:1 비율)만 global layer이므로, 전체적인 메모리 사용량은 full attention 대비 현저히 낮다.
2.4. RoPE Rescaling for Long Context

RoPE Rescaling은 128K token의 long context를 지원하기 위한 기술이다. 모델은 처음부터 128K sequence로 학습하는 대신, 32K sequence로 pre-training 후 RoPE rescaling을 통해 4B, 12B, 27B model을 128K token으로 확장한다.
RoPE는 각 위치에 rotation angle을 할당하여 위치 정보를 인코딩한다. 표준 RoPE는 학습 시 본 적 없는 긴 위치에 대해 extrapolation을 시도하지만, 먼 거리의 단어들이 매우 유사한 embedding 값을 가지게 되어 상대적 위치를 구분하기 어려워진다.
"Extending Context Window of Large Language Models via Positional Interpolation" (Chen et al., 2023)에서 제안한 Position Interpolation은 이를 interpolation 문제로 재구성한다. 위치 인덱스를 스케일링하여 모델이 학습한 원래 범위 내에 유지하는 방식이다. 예를 들어, 2,048 token으로 학습된 모델이 4,096 token을 처리해야 할 때, 위치 4,096을 위치 2,048로 매핑하여 rotation angle이 모델이 익숙한 범위 내에 있도록 한다. Scaling factor는 s = new_context_length / old_context_length로 계산되며, 이는 RoPE의 rotation angle 계산에 적용된다.
핵심 아이디어
- 32K sequence로 pre-training 후 RoPE rescaling으로 128K로 확장
- positional interpolation과 유사한 과정 사용
- Scaling factor 8이 실용적으로 잘 작동함 (128K / 32K = 4이지만, 실제로는 8 사용)
세부사항
- RoPE Base Frequency 조정: Global self-attention layer의 RoPE base frequency를 Gemma 2의 10k에서 1M으로 증가시킴. 이는 긴 컨텍스트에서 더 정밀한 위치 인코딩을 가능하게 한다.
- Local Layer Frequency 유지: Local self-attention layer는 10k frequency 유지
- Positional Interpolation: Global self-attention layer의 span을 확장하기 위해 positional interpolation 과정 적용. 위치 인덱스를 스케일링하여 학습 범위 내에 유지
- Scaling Factor: 실험적으로 scaling factor 8이 효과적임을 확인
2.5. Knowledge Distillation
Gemma 3는 사전 학습 단계에서 Knowledge Distillation을 적용하여 경량 model의 성능을 향상시켰다. 이를 통해 Gemma3-4B-IT가 Gemma2-27B-IT와 경쟁력 있는 성능을 달성할 수 있었으며, 작은 model이 큰 model의 성능에 근접할 수 있게 해주어 경량 model의 실용성을 크게 향상시켰다. 또한 novel post-training recipe와 결합하여 수학, 추론, 채팅, 지시 수행, 다국어 능력을 크게 향상시켜 경량 model도 충분히 강력한 성능을 달성할 수 있게 했다.
3. Experimental Results
Gemma 3는 경량 모델임에도 불구하고 강력한 성능을 보였다. Gemma3-4B-IT는 Gemma2-27B-IT와 경쟁력 있는 성능을 달성했으며, 이는 Knowledge Distillation과 효율적인 아키텍처 설계의 효과를 보여준다. 작은 model이 큰 model의 성능에 근접할 수 있다는 것은 경량 model의 실용성을 크게 향상시킨다.
Gemma3-27B-IT는 Gemini-1.5-Pro와 비교 가능한 성능을 보였으며, 특히 수학, 추론, 채팅, 지시 수행 능력에서 크게 향상되었다. 이는 novel post-training recipe의 효과를 보여주며, 경량 모델도 충분히 강력한 성능을 달성할 수 있음을 입증한다.
Extended Context 능력은 긴 문서 처리와 멀티턴 대화에서 실질적인 이점을 제공했다. 128K token context로 긴 문서를 한 번에 처리할 수 있었으며, 문서 전체의 맥락을 유지하면서 특정 부분에 대한 질문에 정확하게 답할 수 있었다. 또한 멀티턴 대화에서도 대화 맥락을 오래 유지할 수 있어, 사용자와의 긴 대화에서도 일관성 있는 응답을 제공할 수 있었다.
Local/Global Attention 혼합 구조는 메모리 효율성을 크게 향상시켰다. 긴 컨텍스트를 처리하면서도 KV-cache 메모리 증가를 제한하여, 소비자용 하드웨어에서도 실행 가능하게 했다.
4. Conclusion
Gemma 3의 기술적 특이점은 경량 model에 멀티모달 능력을 효율적으로 추가한 설계에 있다. Local/Global Attention 혼합 구조는 5:1 비율로 local layer(1024 token span)와 global layer를 배치하여, 128K token context를 지원하면서도 KV-cache 메모리 증가를 제한한다. 이는 모든 token에 대해 global attention을 수행하는 기존 방식의 메모리 문제를 해결하는 핵심 메커니즘이다. SigLIP Vision Encoder는 이미지를 256개의 고정된 soft token으로 encoding하여 메모리 사용량을 예측 가능하게 하며, Pan and Scan 방법으로 다양한 종횡비의 이미지를 효율적으로 처리한다. Knowledge Distillation은 사전 학습 단계에서 사용되어 Gemma3-4B-IT가 Gemma2-27B-IT와 경쟁력 있는 성능을 달성할 수 있게 했다.
이러한 기술적 설계를 통해 경량 model(1B ~ 27B parameter)이 소비자용 하드웨어에서도 실행 가능하면서도 강력한 멀티모달 성능을 제공한다.
'🏛 Research > Multi-modal' 카테고리의 다른 글
| [MLLM] GLM-4.5V 테크니컬 리포트 리뷰 (0) | 2026.02.18 |
|---|---|
| [MLLM] InternVL3.5 테크니컬 리포트 리뷰 (0) | 2026.02.18 |
| Qwen3-VL 테크니컬 리포트 리뷰 | VLM | MLLM (2) | 2026.01.10 |
| [논문 리뷰] Visual Instruction Tuning | LLaVA Model (1) | 2024.12.04 |
| [논문 리뷰] BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models (0) | 2024.12.04 |