[논문 리뷰] Visual Instruction Tuning | LLaVA Model
·
🏛 Research/Multi-modal
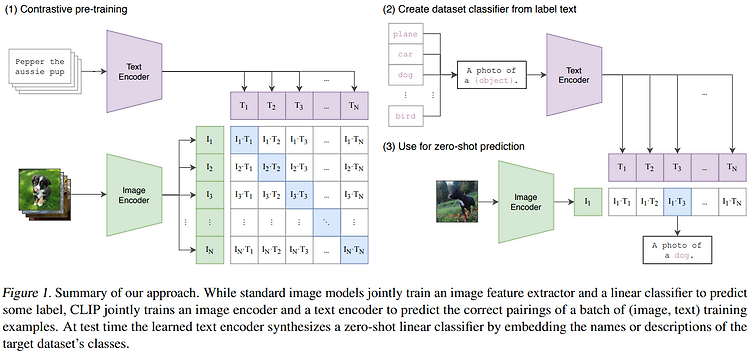
💡 LLaVA 1. 연구 주제와 주요 기여 이 연구는 텍스트와 이미지를 함께 이해하고 처리할 수 있는 멀티모달 모델 LLaVA를 제안하고 있어요. 특히 Visual Instruction Tuning을 통해 멀티모달 작업에서 사용자의 지시를 따르고, 복잡한 이미지와 텍스트 기반 작업을 수행할 수 있도록 모델을 설계했어요. 기존의 이미지-텍스트 페어 데이터(예: COCO)를 활용한 학습에서 한 발 더 나아가, GPT-4를 활용해 이미지 설명 캡션을 바탕으로 질문과 답변 형식의 새로운 학습 데이터를 생성했답니다.새로운 데이터셋 생성 방법: GPT-4를 활용해 기존 이미지-텍스트 페어를 멀티모달 지시-응답 데이터로 자동 변환하는 데이터 생성 파이프라인을 개발했어요. 이를 통해 다양한 멀티모달 작업에 활용 가능..