1. 인트로

1.1 트랜스포머의 영향
최근 딥러닝에서는 자연어 처리에서 GPT, BERT 같은 트랜스포머가 사실상 표준이 되었고, 이미지 분류에서도 ViT(Vision Transformer)가 ResNet을 대체하는 흐름을 보이고 있다. 하지만 이상하게도 이미지 생성 분야, 특히 diffusion 기반 모델에서는 해당 논문이 발표되기 전까진 convolutional U-Net이 널리 쓰이고 있다.
1.2 diffusion에서 왜 아직도 U-Net인가?
Stable Diffusion, DALL·E 2 같은 유명한 생성 모델들도 모두 noise를 점진적으로 제거하는 neural network로 U-Net을 사용한다. diffusion process에서 timestep마다 노이즈를 제거하는 ε_θ(x_t)을 예측할 때 convolutional U-Net이 당연한 선택처럼 사용되어 왔기 때문이다.
2. 이 논문이 제안한 것

2.1 핵심 아이디어: U-Net을 완전히 transformer로 대체
"Scalable Diffusion Models with Transformers (DiT)" 논문은 diffusion 모델의 backbone을 convolution U-Net에서 완전히 Vision Transformer(ViT) 기반으로 바꿀 수 있음을 보여준다. 즉, noise prediction을 위한 U-Net 대신 pure transformer를 사용한 것이다.
여기서 중요한 것은 논문 제목에 있는 "Scalable"이라는 표현이다. 이 논문은 U-Net을 transformer로 단순히 바꾸는 데 그치지 않고, transformer의 크기(depth, width)나 patch sequence 길이를 늘려도 성능이 꾸준히 좋아지는 scaling law를 실험으로 보여주었다. 즉, ViT 기반 diffusion은 연산량(Gflops)을 증가시킬수록 FID가 지속적으로 낮아지며 더 좋은 샘플을 생성하는 경향을 보였다. 이는 기존 U-Net에서는 확실히 보장되지 않던 부분이다.
결과적으로 이 논문은 diffusion에서 convolutional inductive bias를 일부 포기하는 대신, transformer의 뛰어난 scalability와 long-range dependency 학습 능력을 가져와 더 대규모 diffusion 모델로 확장하기 좋은 구조임을 강조한다.
2.2 Latent diffusion 구조는 유지
Stable Diffusion 같은 latent diffusion 모델(LDM)과 마찬가지로, 이 논문도 이미지를 바로 생성하는 것이 아니라 먼저 VAE encoder로 latent 공간으로 압축한 뒤 diffusion을 수행한다. 예를 들어 256×256 이미지는 VAE를 통해 32×32×4 latent로 downsample된다.
[이미지]
↓ VAE Encoder
[latent z]
+ noise → x_t
↓
[Transformer Denoiser]
→ ε_θ(x_t)
↓ Scheduler (iterative denoise)
[z₀]
↓ VAE Decoder
[복원된 이미지]이 pipeline에서 기존 U-Net만 Transformer로 대체한 것이다.
2.3 Patchify & Transformer
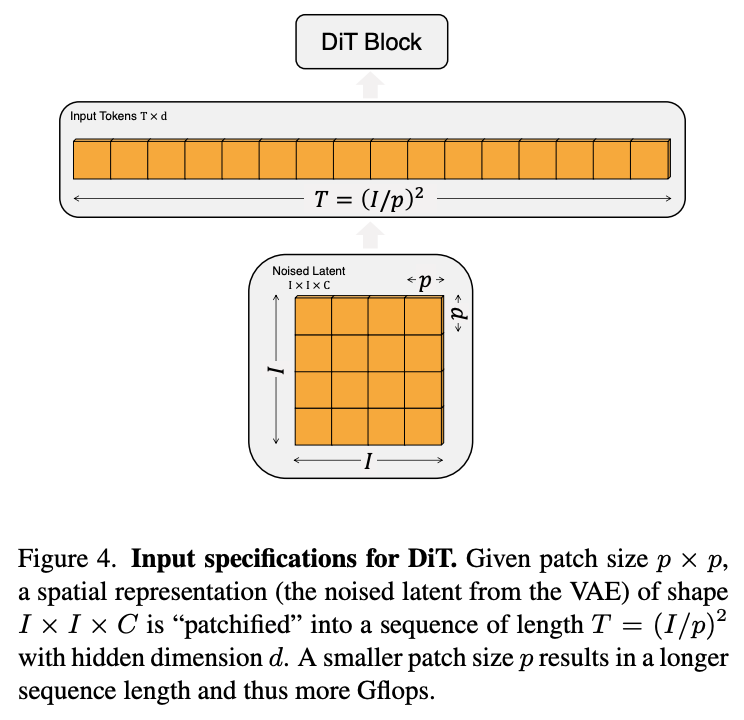
Transformer를 사용하기 위해서는 latent feature map을 patch sequence로 변환해야 한다. 논문에서는 latent feature (예: 32×32×4)를 patchify 해서 (patch size p=4라면) 총 8×8=64개의 sequence token으로 만든다. 이후 standard ViT block을 stack해 noise prediction을 수행한다.
또 diffusion step t, class label c을 transformer block에 넣기 위해 여러 conditioning 방식을 실험했다.
2.4 Conditioning 방식들

논문에서는 transformer를 diffusion backbone으로 사용하면서 conditioning(조건 주입)을 어떻게 하면 가장 효과적인지 다양한 방법을 실험했다.
여기서 conditioning이란 diffusion 과정에서 timestep(몇 번째 denoise step인지)이나 class(label)를 네트워크에 주입해,
noise 제거가 해당 조건에 맞게 진행되도록 유도하는 과정이다.
이는 diffusion의 핵심 아이디어이기도 하다. 예를 들어 timestep t가 클수록 (아직 noise가 많은 상태) 더 rough하게 denoise하고, t가 작아지면 (이미지에 가까운 상태) 더 fine하게 denoise해야 한다. 또 class label이 'cat'이면 고양이 모양으로, 'dog'이면 강아지 모양으로 점진적으로 noise를 제거하며 이미지를 만들어야 한다.
사실 이 논문에서 제안하는 바는 Unet → ViT, conditioning 방법 최적화 이 두 가지라고 보면 된다.
2.4.1 In-context conditioning
- timestep embedding과 class embedding을 transformer의 patch token sequence에 단순히 concat한다.
- latent patch sequence가 [patch_1, patch_2, ..., patch_N] 이라면 [timestep_embed, class_embed, patch_1, patch_2, ..., patch_N] 으로 transformer에 넣는다.
- 장점: 구조를 따로 바꿀 필요 없이 standard ViT block을 그대로 쓸 수 있다.
- 단점: conditioning 정보가 다른 patch token과 완전히 똑같이 처리되므로, timestep이나 class signal을 강하게 주기 어렵다.
2.4.2 Cross-Attention
- transformer block에 self-attention 뒤 cross-attention layer를 추가해, timestep과 class embedding을 key/value로 넣고 latent token을 query로 사용한다.
- patch tokens → self-attention → cross-attention(t,c) → MLP
- 장점: diffusion에서 prompt-text conditioning을 할 때 자주 쓰는 방식으로, conditioning signal을 직접 attention으로 강하게 연결할 수 있다.
- 단점: self-attention만 쓸 때보다 연산량이 약 15% 늘어나고, 학습이 조금 더 불안정할 수 있다.
2.4.3 adaLN (Adaptive LayerNorm)
- transformer block 내부의 LayerNorm을 보통은 normalized_x = (x - mean) / std; output = normalized_x * γ + β 이렇게 처리하는데, 여기서 γ와 β를 timestep과 class embedding을 넣은 MLP의 출력으로 대체한다.
- γ(t,c), β(t,c) = MLP([embedding(t), embedding(c)]); adaLN(x) = (x - mean) / std * γ(t,c) + β(t,c)
- 장점: conditioning 정보를 transformer의 모든 feature에 고르게 적용할 수 있다.
- 단점: residual branch에 강하게 들어가면 학습 초기 불안정할 수 있다.
2.4.4 adaLN-Zero
- adaLN과 같지만, residual branch에 적용되는 scaling factor를 처음에 0으로 초기화(identity) 한다.
- output = x + α * F(adaLN(x)) 여기서 α를 학습 초기에 0으로 두어, 학습을 진행하면서 점차 conditioning의 영향력이 커지도록 한다.
- 장점
- 학습 초기에 conditioning으로 인한 gradient explosion이나 unstable learning을 막아준다.
- 논문 실험에서 가장 낮은 FID를 기록했으며, diffusion stability에도 가장 좋았다.
🔎 LayerNorm ?
LayerNorm은 transformer block에서 입력을 normalize하는 연산이다. hidden_dim 방향으로 평균을 0, 표준편차를 1로 맞춰 normalized_x = (x - mean) / std로 만든 후, γ, β를 곱해 다시 스케일과 쉬프트한다. 이렇게 해서 feature의 분포를 일정하게 유지해 gradient 흐름이 안정적이게 한다. adaLN은 이 γ, β를 timestep과 class에 따라 adaptive하게 만들어 조건에 맞게 feature distribution 자체를 바꾼다.
3. 실험
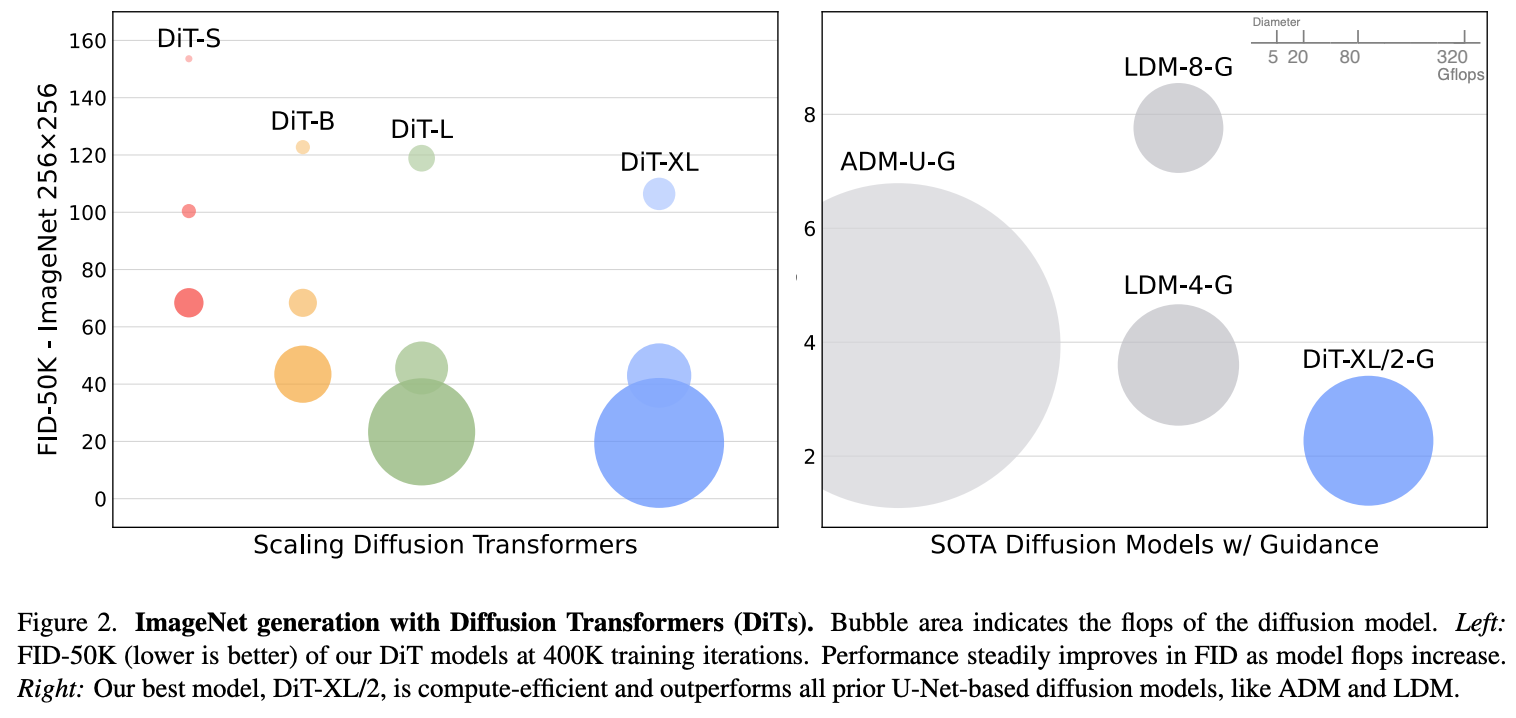
3.1 Scaling 실험: 더 큰 Transformer = 더 좋은 성능
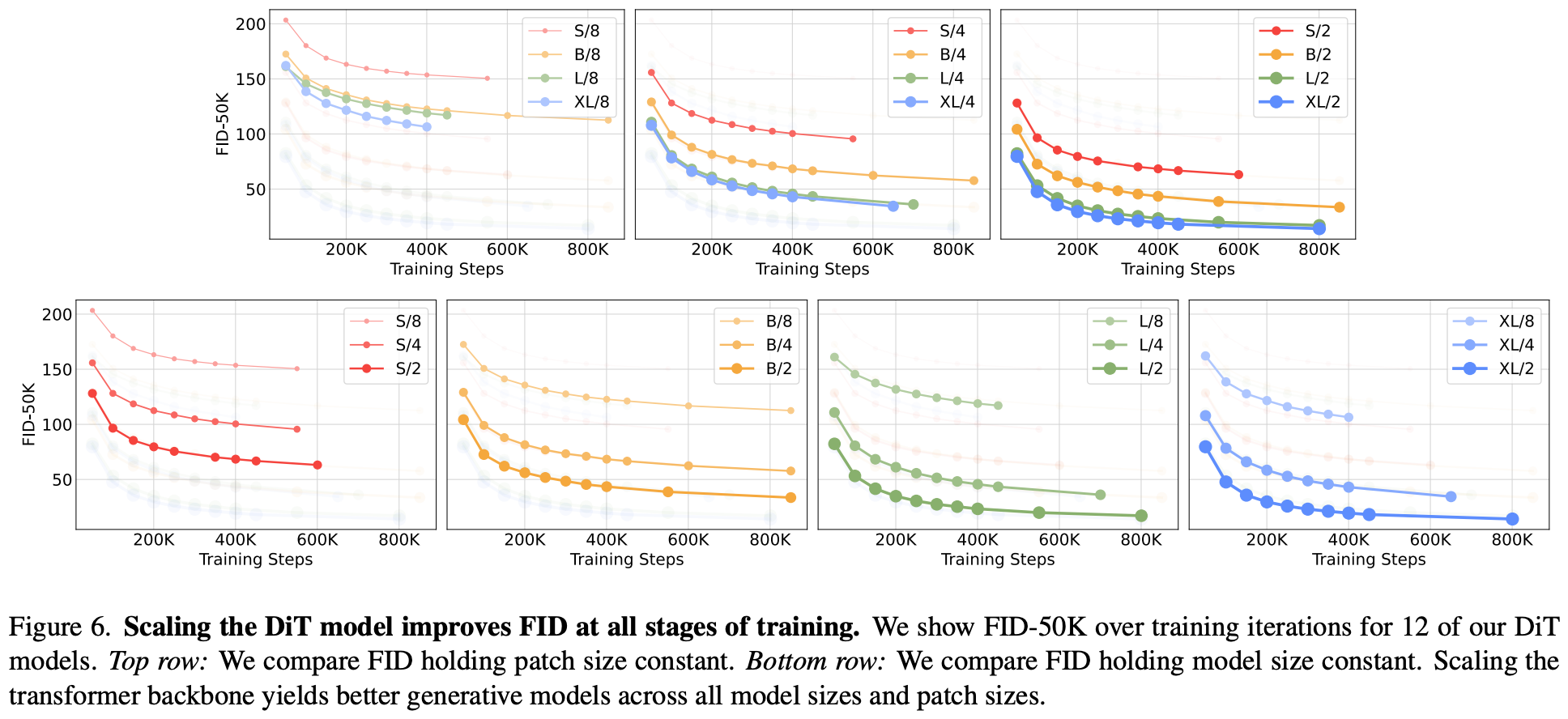
논문에서는 DiT를 Tiny~XL까지 depth/width를 점점 키우며 실험했고, patch size도 8→4→2로 줄이며 토큰 개수를 늘렸다. 그 결과 transformer Gflops가 늘어날수록 FID가 일관되게 낮아지는 scaling law를 확인했다.
예를 들어 DiT-XL/2 (patch=2, 가장 compute intensive)는 ImageNet 256×256에서 FID=2.27로 기존 best인 LDM보다 훨씬 낮은 FID를 기록했다.
3.2 Conditioning block 비교 실험
같은 DiT-XL/2 모델에 in-context, cross-attention, adaLN, adaLN-Zero만 다르게 적용해봤을 때 adaLN-Zero가 가장 안정적이고 낮은 FID를 보였다. residual branch를 처음에 0으로 두고 점진적으로 conditioning을 적용하게 한 것이 학습 초기에 불안정한 divergence를 막아준 것이다.
직접 DiT 모델을 학습해 보고 싶다면, 아래 깃헙 레포를 참고하자! GPU 리소스 없이도 가볍게 학습해볼 수 있게 세팅해두었다.
https://github.com/ldj7672/Vision-AI-Tutorials/blob/main/Image_Generation/DiT_FashionMNIST/README.md
Vision-AI-Tutorials/Image_Generation/DiT_FashionMNIST/README.md at main · ldj7672/Vision-AI-Tutorials
Computer Vision & AI를 쉽게 배우고 실습할 수 있는 예제 모음입니다. Contribute to ldj7672/Vision-AI-Tutorials development by creating an account on GitHub.
github.com
이 논문은 diffusion에서 backbone을 transformer로 바꿔도 전혀 문제가 없으며, 오히려 훨씬 더 잘 scaling되고 더 나은 샘플 품질을 보여준다는 것을 명확하게 입증했다. 이후 Stable Diffusion 3 (SD3) 같은 최신 모델들이 DiT 기반(MMDiT) 구조를 채택한 것도 이런 연구의 연장선이라 할 수 있다.
Diffusion 기술을 공부하는 중이라면 꼭 거쳐가야할 논문이며, DiT에 사용되는 트랜스포머 아키텍처와 conditioning 방법 등을 위주로 보면 도움이 되지 않을까 생각한다.
'🏛 Research > Image•Video Generation' 카테고리의 다른 글
| [Gen AI] 이미지 생성 모델의 평가 지표 정리 | FID, IS, CLIP Score, LPIPS,... (1) | 2025.08.01 |
|---|---|
| [Gen AI] Flow Matching & Rectified Flow 설명 (2) | 2025.07.31 |
| [Gen AI] Diffusion 모델 샘플링 & 학습 트릭 정리 (4) | 2025.07.08 |
| [Gen AI] LDM (Latent Diffusion Models) 개념 설명 (1) | 2025.06.29 |
| [Gen AI] Diffusion Model과 DDPM 개념 설명 (0) | 2025.03.31 |