생성 모델에서 Diffusion은 고해상도 이미지를 만들어내는 핵심 기술로 자리 잡았지만, DDPM처럼 픽셀 공간에서 직접 노이즈를 다루는 방식에는 치명적인 단점이 있었다. 바로 연산과 메모리 효율이다.
[Gen AI] Diffusion Model과 DDPM 개념 설명
생성 모델에서 Diffusion 모델은 고해상도 이미지를 생성하는 핵심 기술로 주목받고 있는데, 이 모델은 노이즈를 점점 제거해가며 이미지를 생성한다는 개념으로, Stable Diffusion, DALL·E 2 등 다양한
mvje.tistory.com
예를 들어, 256×256 해상도의 이미지를 직접 디퓨전(픽셀 단위로 노이즈를 넣고 제거)하려면, 수백 MB에 달하는 feature를 반복적으로 처리해야 한다. 고해상도일수록 이 부담은 기하급수적으로 커져, GPU 메모리 한계에 금세 도달한다. 이 문제를 해결하기 위해 등장한 것이 바로 Latent Diffusion Models (LDM) 이다.
💡LDM training을 해보고 싶다면 → LDM_MNIST
Vision-AI-Tutorials/Image_Generation/LDM_MNIST at main · ldj7672/Vision-AI-Tutorials
Computer Vision & AI를 쉽게 배우고 실습할 수 있는 예제 모음입니다. Contribute to ldj7672/Vision-AI-Tutorials development by creating an account on GitHub.
github.com
1. LDM이란?
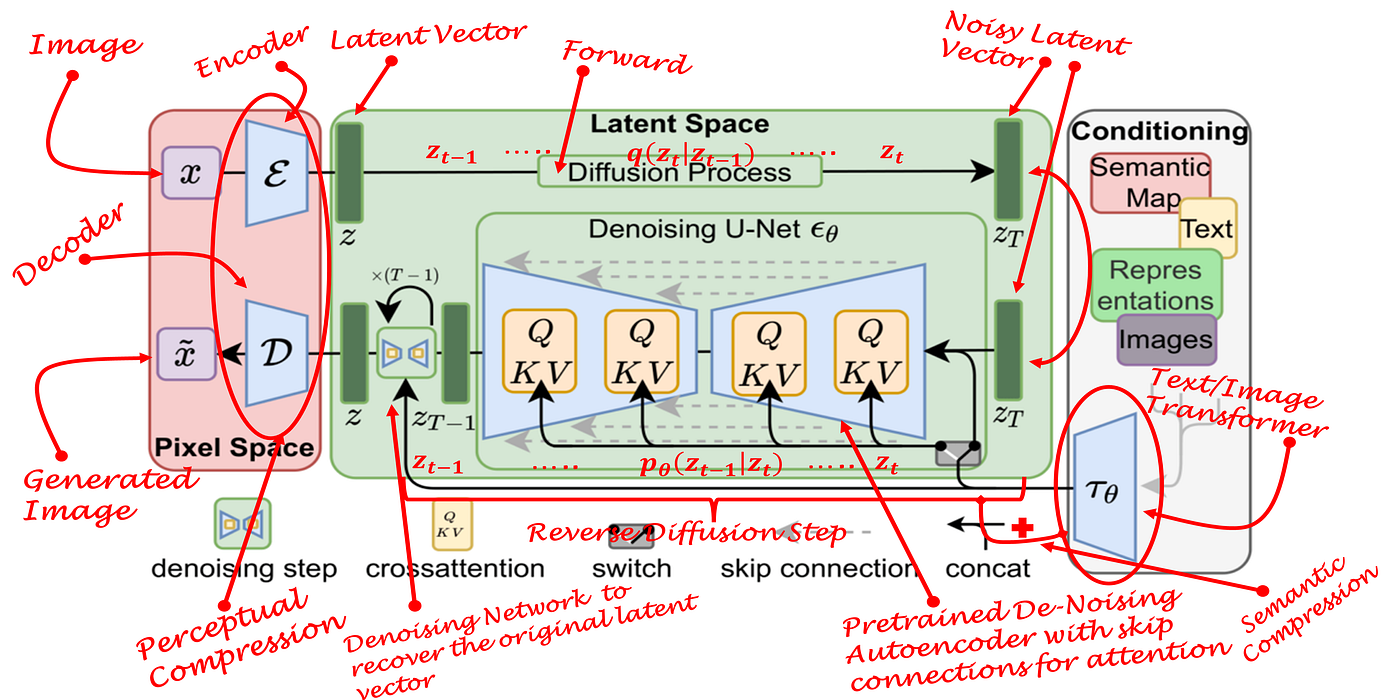
LDM(Latent Diffusion Model)은 2022년 CVPR에 발표된 논문 “High-Resolution Image Synthesis with Latent Diffusion Models”에서 처음 제안되었다. 이 모델은 Stable Diffusion의 바로 그 원형이며, 기존 DDPM 방식의 가장 큰 병목인 픽셀 공간에서의 디퓨전을 latent 공간으로 옮기는 전략을 취했다.
즉, LDM은 먼저 고해상도 이미지를 VAE(Variational Autoencoder)를 통해 훨씬 작은 latent 공간으로 인코딩한다. 그 후 이 latent 공간에서 DDPM과 동일한 방식으로 노이즈를 주입하고 제거하는 과정을 학습한다. 마지막에 이 latent를 다시 디코딩해 원래의 이미지로 복원한다. 이렇게 하면 디퓨전이 처리해야 할 feature map 크기가 수십 배 작아져, 훨씬 빠르고 적은 자원으로 고해상도 이미지를 생성할 수 있게 된다.
예를 들어, 256×256×3 크기의 이미지를 VAE로 인코딩하면 32×32×4 정도의 latent로 변환된다. 여기서 디퓨전을 수행하면, 원래보다 연산량이 약 60배 가까이 줄어든다. 그 결과 일반적인 소비자 GPU로도 Stable Diffusion 같은 고해상도 이미지 생성이 가능해졌다.
진짜 간단히 말하면,
LDM은 <이미지>를 VAE Encoder에 통과시켜 <latent vector>로 변환하고, 이 latent vector에 노이즈를 주입한 뒤,
Unet이 그 노이즈를 예측하도록 학습하는 모델이다. 그래서 실제 LDM은 VAE + Unet으로 구성되며, 입력 데이터는 이미지이고, 조건 정보로는 클래스나 텍스트 임베딩 등이 함께 활용될 수 있다.
2. LDM의 구조와 학습 과정
LDM은 크게 세 가지 단계로 이루어진다.
2.1 Encoding: 이미지 → latent
원본 이미지 x₀를 VAE Encoder를 통해 latent z₀로 압축한다.
x₀ → Encoder → z₀
이 latent z₀는 이미지의 구조적, 시각적 정보를 유지하지만, 픽셀 단위의 노이즈에는 덜 민감한 compact representation이다. VAE 학습은 diffusion 학습 이전에 먼저 완료되며, 이후에는 Encoder와 Decoder를 고정시켜 사용한다.
2.2 Latent Diffusion: latent에서 noise 주입과 예측
이제 기존 DDPM에서 픽셀 공간에서 하던 것을 latent 공간에서 수행한다.
Forward Process
z₀ → z₁ → z₂ → ... → z_Tzₜ = sqrt(ᾱ_t) * z₀ + sqrt(1-ᾱ_t) * ε- z₀에 시간 step t에 따라 점점 노이즈를 더해 zₜ를 만든다.
- 학습에서는 x₀에서 바로 z₀를 얻은 뒤, random noise ε과 timestep t를 샘플링해식으로 한 번에 만든다.
- 이는 DDPM에서의 방식과 완전히 동일하다.
아래는 time embedding과 class embedding을 Unet에 직접 주입하는 형태의 단순화된 PyTorch 예제 코드이다.
class LDMUNet(nn.Module):
def __init__(self, num_classes=10):
super().__init__()
# Time embedding (128 → 512)
self.time_mlp = nn.Sequential(
nn.Linear(128, 512), nn.ReLU(), nn.Linear(512, 512)
)
# Class embedding (256 → 512)
self.class_emb = nn.Embedding(num_classes + 1, 256)
self.class_mlp = nn.Sequential(
nn.Linear(256, 512), nn.ReLU(), nn.Linear(512, 512)
)
# Input projection
self.input_proj = nn.Conv2d(4, 64, 3, padding=1) # [4 → 64]
# Encoder
self.enc1 = nn.Conv2d(64 + 512, 128, 4, stride=2, padding=1) # 32→16
self.enc2 = nn.Conv2d(128 + 512, 256, 4, stride=2, padding=1) # 16→8
self.enc3 = nn.Conv2d(256 + 512, 512, 4, stride=2, padding=1) # 8→4
# Middle
self.middle1 = nn.Conv2d(512 + 512, 768, 3, padding=1)
self.middle2 = nn.Conv2d(768 + 512, 512, 3, padding=1)
# Decoder
self.dec3 = nn.ConvTranspose2d(1024 + 512, 256, 4, stride=2, padding=1) # 4→8
self.dec2 = nn.ConvTranspose2d(512 + 512, 128, 4, stride=2, padding=1) # 8→16
self.dec1 = nn.ConvTranspose2d(192 + 512, 64, 4, stride=2, padding=1) # 16→32
# Output
self.output_proj = nn.Conv2d(64 + 512, 4, 3, padding=1) # back to [4]
def forward(self, x, t, class_labels=None):
"""
- x: [batch, 4, 32, 32] (latent z_t)
- t: [batch] timestep
- class_labels: [batch] class index
"""
# Create condition embedding
t_emb = self.time_mlp(t) # [batch, 512]
if class_labels is None:
class_labels = torch.full(
(x.size(0),), self.class_emb.num_embeddings - 1,
device=x.device, dtype=torch.long
)
c_emb = self.class_mlp(self.class_emb(class_labels)) # [batch, 512]
cond_emb = (t_emb + c_emb).unsqueeze(-1).unsqueeze(-1) # [batch, 512, 1, 1]
# Input projection
x = self.input_proj(x) # [batch, 64, 32, 32]
# Encoder with condition
x = torch.cat([x, cond_emb.expand(-1, -1, 32, 32)], dim=1)
x1 = F.relu(self.enc1(x)) # [batch, 128, 16, 16]
x1_cat = torch.cat([x1, cond_emb.expand(-1, -1, 16, 16)], dim=1)
x2 = F.relu(self.enc2(x1_cat)) # [batch, 256, 8, 8]
x2_cat = torch.cat([x2, cond_emb.expand(-1, -1, 8, 8)], dim=1)
x3 = F.relu(self.enc3(x2_cat)) # [batch, 512, 4, 4]
# Middle with condition
x3_cat = torch.cat([x3, cond_emb.expand(-1, -1, 4, 4)], dim=1)
x_mid = F.relu(self.middle1(x3_cat)) # [batch, 768, 4, 4]
x_mid = torch.cat([x_mid, cond_emb.expand(-1, -1, 4, 4)], dim=1)
x_mid = F.relu(self.middle2(x_mid)) # [batch, 512, 4, 4]
# Decoder with condition
x_mid_cat = torch.cat([x_mid, x3, cond_emb.expand(-1, -1, 4, 4)], dim=1)
x = F.relu(self.dec3(x_mid_cat)) # [batch, 256, 8, 8]
x = torch.cat([x, x2, cond_emb.expand(-1, -1, 8, 8)], dim=1)
x = F.relu(self.dec2(x)) # [batch, 128, 16, 16]
x = torch.cat([x, x1, cond_emb.expand(-1, -1, 16, 16)], dim=1)
x = F.relu(self.dec1(x)) # [batch, 64, 32, 32]
# Output projection with final condition
x = torch.cat([x, cond_emb.expand(-1, -1, 32, 32)], dim=1)
return self.output_proj(x) # [batch, 4, 32, 32]- 위 Unet 예제 코드는 timestep embedding + class embedding을 더해 만든 cond_emb를 encoder와 decoder에 주입해, 각 단계에서 diffusion 과정의 시간과 조건을 반영한다.
- cond_emb는 원래 1D vector이지만, 인코더/디코더에서 spatial feature map과 concat하기 위해 [batch, 512, H, W]로 broadcast해서 사용한다.
- 이렇게 간단화된 구조로도 LDM의 "time + class guided Unet" 개념을 직관적으로 실험할 수 있다.
Reverse Process
noise_pred = UNet(zₜ, t)L = E[||ε - noise_pred||²]- 학습 대상인 UNet은 이 zₜ와 t를 입력받아, zₜ에 섞여 있는 노이즈 ε을 예측한다.
- 그리고 실제 noise ε과 MSE Loss를 통해 차이를 줄여나간다.
- 이런 반복을 통해, 다양한 t에서 노이즈가 포함된 zₜ를 보고 그 안에 어떤 노이즈가 들어있는지 잘 예측할 수 있도록 학습된다.
2.3 Decoding: latent → 이미지 복원
생성이 끝난 latent z₀는 고정된 VAE Decoder를 통해 다시 고해상도 이미지로 복원된다.
z₀ → Decoder → x̂₀
이 과정을 통해 latent에서 잘 만들어진 구조가 디코딩되어 픽셀 공간의 자연스러운 이미지로 바뀐다.
정리하면...
✅ LDM 학습 플로우
[이미지 x₀]
|
v
[VAE Encoder]
|
v
[latent z₀]
|
v
[Noise injection]
zₜ = sqrt(ᾱ_t) * z₀ + sqrt(1-ᾱ_t) * ε
|
v
+-------------------+
| Unet(zₜ, t, cond)|
| → noise_pred |
+-------------------+
|
v
[MSE Loss]
= || noise_pred - ε ||²
|
v
[Backpropagation]
3. Inference & DDIM Sampling
생성(Inference) 단계에서는 완전히 랜덤한 latent noise z_T에서 시작한다. 그리고 학습된 UNet을 이용해 점진적으로 노이즈를 제거하며 z_{T-1}, z_{T-2}, ..., z₀으로 이동한다.
이때 DDPM 방식은 수백~수천 스텝을 거치며 조금씩 노이즈를 줄이는 stochastic sampling을 한다. 반면 LDM은 일반적으로 DDIM(Denoising Diffusion Implicit Models) 방식을 사용해, 같은 β 스케줄을 적은 스텝으로 deterministic하게 뛴다. DDIM은 ODE(확률적 미분 방정식 → 결정적 미분 방정식) 해석을 이용해 noise sampling term을 제거하거나 조절함으로써,
- 더 적은 step에서도 깨끗한 결과를 만들 수 있고,
- 동일한 z_T에서 항상 같은 x̂₀를 생성할 수도 있다.
즉, DDIM은 한 스텝당 더 많은 노이즈를 제거하며 이동하고, η 파라미터를 통해 sampling stochasticity를 조절할 수도 있다. 이 덕분에 보통 50~100 스텝 정도만으로도 좋은 결과를 낸다.
정리하면...
✅ LDM 학습 플로우
[Random latent z_T ~ N(0,I)]
|
v
for t = T...1:
+-------------------+
| Unet(zₜ, t, cond)|
| → noise_pred |
+-------------------+
|
v
[Denoise step]
z_{t-1} = f(zₜ, noise_pred, t)
(반복)
|
v
[latent z₀]
|
v
[VAE Decoder]
|
v
[이미지 x̂₀ (샘플)]
4. Text-to-Image (T2I)와 LDM
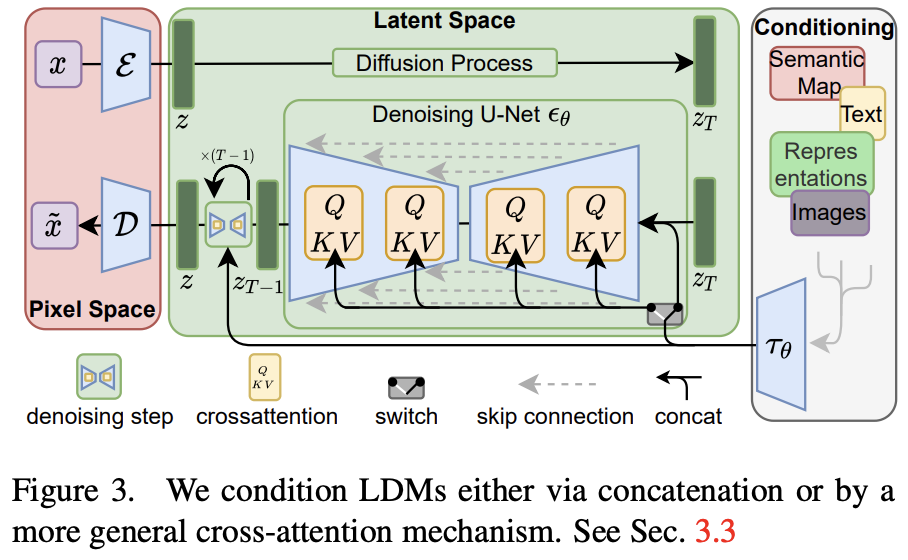
Stable Diffusion은 이 LDM 구조를 그대로 가져와, UNet에 text embedding을 Cross-Attention으로 연결해 조건부 생성을 가능하게 했다. 즉, T2I는 UNet의 입력으로
(zₜ, t, text_embedding)
을 주어,
- zₜ와 t를 보고 noise를 예측하되,
- attention query-key-value에 text embedding을 넣어 prompt에 맞게 이미지를 만들어간다.
결과적으로 “astronaut riding a horse” 같은 문장을 입력하면, 이 조건에 맞게 latent 공간에서 노이즈를 제거해나가면서 원하는 이미지가 탄생한다.
LDM은 “픽셀 공간 대신 latent 공간에서 diffusion을 수행”하여 메모리와 속도를 획기적으로 개선한 DDPM의 확장판이며,
이를 통해 Stable Diffusion 같은 고해상도 Text-to-Image 생성이 가능해졌다. 이러한 방식은 이후 ControlNet, Inpainting, 3D NeRF reconstruction 등 다양한 디퓨전 기반 기술의 표준이 되었으며, 여전히 멀티모달 생성(텍스트-이미지-오디오) 분야에서 활발히 연구되고 있다.
'🏛 Research > Image•Video Generation' 카테고리의 다른 글
| [Gen AI] Diffusion Transformer (DiT) 완벽 이해하기! (5) | 2025.07.15 |
|---|---|
| [Gen AI] Diffusion 모델 샘플링 & 학습 트릭 정리 (4) | 2025.07.08 |
| [Gen AI] Diffusion Model과 DDPM 개념 설명 (0) | 2025.03.31 |
| [논문 리뷰] DREAMFUSION: TEXT-TO-3D USING 2D DIFFUSION (0) | 2025.03.23 |
| [논문 리뷰] Zero-1-to-3: Zero-shot One Image to 3D Object | Single-view object reconstruction (0) | 2025.03.22 |