1. Intro

최근 Back to Basics: Let Denoising Generative Models Denoise (JiT) 논문이 Diffusion 분야에서 꽤 핫한 연구이다. 핵심은 매우 단순한데, "Diffusion 모델은 본래 깨끗한 이미지를 복원하는 모델인데, 왜 대부분의 구현은 노이즈(ϵ)나 v(velocity)만 예측할까?" JiT는 바로 이 질문에서 출발해, "그냥 클린 이미지(x)를 직접 예측하면 더 잘 된다"라는 매우 직관적이지만 강력한 결론을 제시한다. 특히 고해상도 픽셀 공간에서는 이 효과가 극적으로 나타난다.
1.1 문제의식: 왜 x-prediction인가?
기존 diffusion 모델은 크게 ϵ-prediction 또는 v-prediction을 사용한다. 그러나 이 두 대상은 노이즈가 크게 포함된 고차원 데이터(latent)이며, 모델이 이를 직접 예측하는 과정에서 높은 capacity를 요구한다.
반면, 자연 이미지 x는 본질적으로 저차원 manifold 위에 존재한다(논문 Fig. 1). 즉, 모델이 예측해야 하는 정보량이 훨씬 적다. 따라서 모델 capacity가 충분하지 않은 상황에서는 오히려 x를 직접 예측하는 것이 훨씬 안정적이라는 점을 이 논문은 매우 설득력 있게 보여준다.
예를 들어, 512×512 이미지의 32×32 패치는 3,072차원에 이르며, 이를 그대로 모델이 다루는 것은 매우 어렵다. 그러나 x는 노이즈보다 구조가 명확하고 manifold 구조가 있기 때문에 모델이 이를 학습하는 데 훨씬 유리하다.
1.2 JiT가 제안하는 핵심 철학
JiT(JUST image Transformers)의 철학은 명확하다.
- ViT를 그대로 사용한다
- 별도의 tokenizer, VAE, perceptual loss 필요 없음
- latent space도 사용하지 않고 오직 픽셀 공간에서 diffusion 수행
- diffusion의 prediction target을 x로 고정한다
즉, "있는 그대로의 Transformer + 있는 그대로의 이미지" 조합만으로 high-resolution diffusion을 성공적으로 수행할 수 있다는 점을 실증했다.
2. Diffusion Prediction Space 분석

논문에서는 x, ϵ, v 세 가지를 prediction target으로 둘 수 있으며, 이를 loss space와 조합하면 총 9가지 경우가 된다고 정리한다. (Table 1) 세 경우는 아래와 같은 성격을 가진다.
2.1 x-prediction
- 모델 출력이 직접 클린 이미지 복원
- manifold 상의 구조적인 데이터를 예측 → 학습 용이
- 256×256 이상 고해상도에서도 안정적으로 동작
- 특히 high-dim pixel space에서 모델 capacity 요구가 가장 낮음
2.2 ϵ-prediction
- 모델이 clean image를 예측하지 않고 노이즈 ϵ를 직접 예측하는 방식
- 노이즈를 예측해야 하므로 고차원 공간 전체를 modeling 필요
- latent space에선 좋짐난, 고차원 pixel-space에서는 모델 capacity가 부족하면 catastrophic failure 발생
- 실험에서 실제로 FID 300 이상으로 붕괴
- DDPM, DDIM, Stable Diffusion(LDM), DiT 등 대부분
2.3 v-prediction
- Flow matching / Rectified Flow 모델
- 여전히 x보다 고차원 정보 + 노이즈가 섞인 off-manifold 값이므로 pixel space에서는 ϵ-prediction처럼 collapse 위험이 존재
핵심 관찰
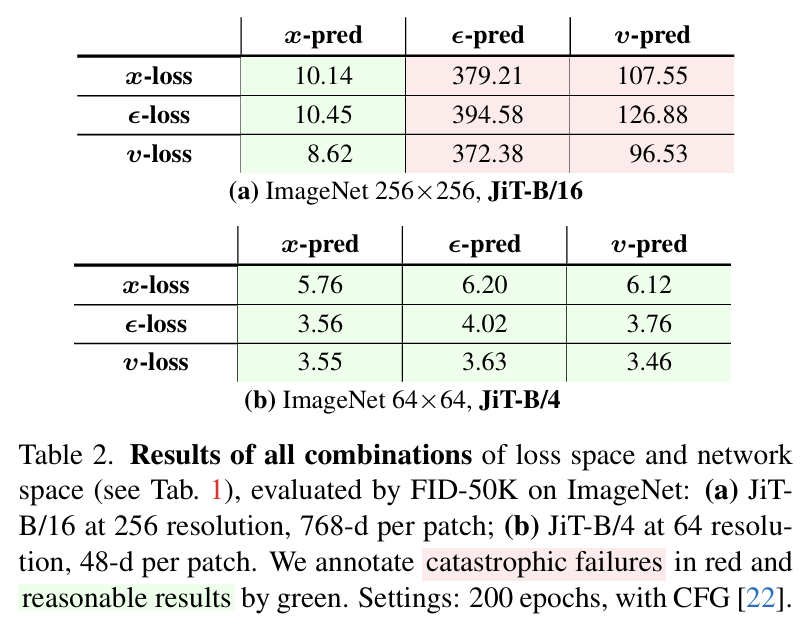
- 256×256 pixel-space에서 ϵ/v prediction은 완전히 붕괴하지만, x-prediction은 정상 작동한다. (Table 2(a))
- 반면 64×64 같은 저해상도에서는 capacity issue가 덜해 9개 조합 모두 준수한 성능을 보임(Table 2(b))
즉, “왜 지금까지 pixel diffusion 모델은 latent space에 의존했는가?”에 대한 답은 명확해진다. ϵ/v를 직접 예측하는 것은 고차원 공간에서 너무 힘들기 때문이고, JiT는 그 방향을 바꿔 x를 직접 예측하면 이 문제가 없어진다는 점을 실험으로 증명한 셈이다.
3. JiT Architecture

JiT(JuST image Transformer)는 이름 그대로 저스트 이미지 Transformer이다. 지금까지의 Diffusion 시스템이 가진 복잡한 구성요소들(예: VAE, latent tokenizer, perceptual loss, multi-scale U-Net 등)을 과감히 제거하고, 원본 이미지(pixels)만 Transformer로 직접 처리하는 방식을 사용한다.
신기하게도(?) 이 단순한 구조가 고해상도 이미지 생성에서 collapse 없이 안정적으로 작동한다.
3.1 Patchify → ViT → Patch Reconstruction
JiT는 이미지를 Vision Transformer(ViT)처럼 고정 크기 패치(tokens)로 나누어 입력한다. 이미지 크기가 512×512라고 가정하면, 패치 사이즈에 따라 입력 토큰의 형태는 아래와 같다.
| Patch Size | Patch Dim | Token 개수 | 특징 |
| 16 x 16 | 768 | 1024 | 토큰 개수가 많아 느림 |
| 32 x 32 | 3072 | 256 | compute 효율 + 패치 단위 표현력 균형 |
| 64 x 64 | 12288 | 64 | 토큰 개수 적어서 빠르지만, 토큰 차원이 매우 큼 |
JiT의 기본 설정은 p=32로, 각 patch는 3072차원(=32×32×3)이라는 매우 큰 벡터다.
중요한 포인트는 일반 Diffusion Transformer는 latent(4~8 channels)나 CNN feature map을 토큰으로 쓰지만, JiT는 아예 원시 pixel 패치를 토큰으로 사용한다. 즉, 더 이상 tokenizer가 필요 없고 이미지 그 자체가 모델의 입력 토큰이다. 이게 가능한 이유가 바로 x-prediction 기반의 안정성 덕분이라고 한다.
3.2 Bottleneck embedding

3072차원의 패치를 그대로 Transformer에 넣으면 메모리와 compute 비용이 매우 크다. 그래서 JiT는 Patch Embedding 단계에서 “병목(bottleneck)” 구조를 사용한다.
3072 (raw patch)
→ 32 (bottleneck)
→ 768 (transformer hidden dim)놀랍게도 bottleneck 크기를 극단적으로 줄여도 성능이 거의 떨어지지 않는다. (논문 Figure 4: d′=32로 줄여도 ImageNet FID 개선)
논문에서 강조하듯 clean image x는 원래 low-dimensional manifold 위에 있기 때문에 raw pixel 정보 전체를 보존할 필요가 없다. 즉, patch의 모든 디테일을 유지할 필요가 없고 manifold 구조만 잘 추출하면 Transformer가 안정적으로 복원할 수 있다.
이 실험은 “pixel diffusion은 patch dimension 때문에 불가능하다”는 기존 생각이 틀렸음을 보여준다.
3.3 Transformer Backbone — Plain ViT, But Diffusionized
Patch Embedding 이후에는 거의 그대로의 ViT가 사용된다.
- SwiGLU FFN
- RMSNorm
- qk-Norm
- Rotary Positional Embedding (RoPE)
- AdaLN-zero 클래스 conditioning
즉, 고도화된 U-Net 구조나 latent 특화 모듈이 아니라, 사실상 일반 언어 모델/비전 모델과 동일한 Transformer로 diffusion을 수행한다. 이는 모델 구조가 특정 도메인에 종속되지 않는다는 의미이기도 하다.
3.4 Output: 모델이 예측하는 것은 항상 Clean Image Patch(x_pred)
여기서 JiT의 핵심이 드러나는데, Transformer는 매 스텝마다 noisy image z_t를 받아 clean image의 패치(x_pred)를 직접 예측한다.
x_pred = net(z_t, t)
물론 이러한 방법으로 한 번에 이미지가 복원되는 것은 아니고 x_pred는 최종 결과물이 아니라 flow 계산을 위한 중간 추정치다.
3.5 v-loss 기반 Flow Matching — x_pred → v_pred

Transformer가 예측한 x_pred로부터 velocity를 계산한다.
v_pred = (x_pred - z_t) / (1 - t)그리고 정답 v와 비교해 v-loss로 학습한다.
이 과정이 중요한 이유는
- x-prediction이 pixel-space에서 안정적
- v-loss가 gradient 균형을 맞춤
- flow matching ODE sampling과 자연스럽게 연결됨
다시 말해, “예측은 x로, 학습은 v로" 하는 것이다.
3.6 Sampling: multi-step ODE solver (Heun/Euler)
JiT는 “clean 이미지를 한 번에 예측하는 모델”이 아니며 여전히 multi-step sampling을 수행한다.
Sampling 절차는
- 초기 noise 이미지 z₀ 생성
- patchify → embedding
- Transformer로 x_pred(t) 예측
- x_pred(t) → v_pred 계산
- z 업데이트 (Heun / Euler ODE step)
- 다시 patchify하여 반복
- 50 step 정도 수행 → 최종 clean image 도달
4. 실험 결과

Figure 2. Toy Experiment를 보면 2차원(2D) 데이터 분포를 만들고, 이를 무작위 projection matrix로 256D, 1024D, 4096D 같은 고차원 공간으로 매핑한 뒤, 이 고차원 데이터를 보고 3가지 방식(x/ϵ/v)으로 다시 원본 분포를 복원하도록 학습시켰다.
결과는 매우 직관적인데,
- x-prediction: D가 아무리 커져도 원래의 2D manifold를 정확히 복원
- ϵ-prediction: 데이터가 blob 형태로 붕괴
- v-prediction: 고차원에서 거의 collapse
즉, 본질적으로 low-dimensional한 구조(x)를 예측하는 것은 쉬운 반면, 고차원 전체에 퍼진 노이즈(ϵ/v)를 직접 예측하는 것은 매우 어렵다는 사실을 보여준다. 이 실험은 “pixel diffusion이 실패한 이유가 compute 때문이 아니라 예측 target 잘못 때문”이라는 JiT 논문의 핵심 주장을 직관적으로 증명한다.


실험 결과를 보면 FID 기준으로 Latent Diffusion(DiT-XL/2) 대비 FLOPs가 훨씬 낮은데 성능은 동급인 것을 확인핦 수 있다. VAE 없이 pixel-space에서 이 수준의 성능이 나온 것 자체가 핵심적인 부분이며, 특히 1024×1024 pixel diffusion이 collapse 없이 돌아간 첫 사례 중 하나라고 볼 수 있다.

Figure 7을 보면 x-prediction이 v-prediction보다 loss가 더 낮고 안정적인 것을 확인할 수 있고, 실제 복원 결과도 x-prediction이 t가 낮을 때 조금 더 품질이 좋다.

이 논문은 그동안 pixel diffusion이 어려웠던 이유는 patch dimension이나 compute 문제 때문이 아니라, ϵ/v 같은 off-manifold, high-dimensional target을 예측했기 때문이라는 점을 명확하게 보여준다. 즉, pixel diffusion의 한계는 구조적 한계가 아니라 설계적 선택의 문제였다는 인사이트를 제시한다.
물론 아쉬운 점은 ImageNet 스케일에서만 실험이 진행되어 T2I나 multi-modal conditioning에 관한 실험이 없다는 점과 GPU 메모리 효율은 LDM 계열보다 떨어질 가능성이 높다는 점도 있다. 하지만, 이 방향이 옳다면 앞으로 관련된 연구가 더 진행되지 않을까 싶다.