반응형
VAE (Variational Autoencoder)
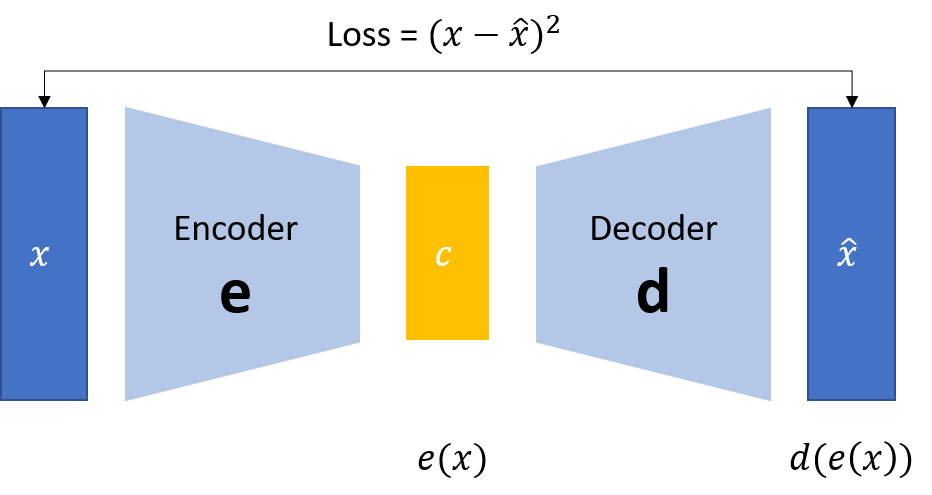
VAE(Variational Autoencoder)는 생성 모델 중 하나로, 주로 차원 축소 및 생성 작업에 사용되는 신경망 아키텍처이다. VAE는 데이터의 잠재 변수를 학습하고 이를 사용하여 새로운 데이터를 생성하는 데 사용되는데, 특히 이미지 및 음성 생성과 같은 응용 분야에서 널리 사용되고 있다. 이러한 VAE는 크게 인코더와 디코더라는 두 부분으로 구성되어 있다.
Autoencoder(오토인코더)와 헷갈릴 수 있는데,
오토인코더는 인풋을 똑같이 복원할 수 있는 latent variable z를 만드는 것이 목적, 즉 인코더를 학습하는 것이 주 목적이고,
VAE의 경우 인풋 x를 잘 표현하는 latent vector를 추출하고, 이를 통해 인풋 x와 유사하지만 새로운 데이터를 생성하는 것이 목적이기에 초점이 디코더에 맞춰져 있다.
- 인코더 (Encoder)
- 인코더는 입력 데이터를 주어진 잠재 공간의 확률 분포로 매핑하는 역할을 수행
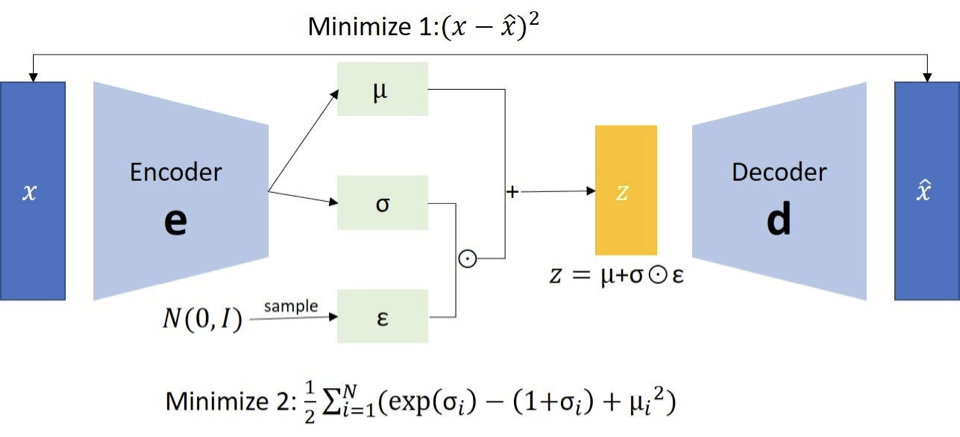
- 주어진 입력 데이터 x에 대해, 인코더는 평균(μ)과 표준 편차(σ)를 가진 정규 분포의 매개변수를 출력
- 입력 데이터 x를 잠재 변수 z로 변환하는 함수로도 볼 수 있음
- 잠재 변수 (Latent Variable)
- latent variable z는 데이터를 특정한 특성이나 요약된 형태로 표현하는데 사용되는 변수이다.
- 이 변수는 인코더에 의해 학습되며, 보통 평균(μ)과 표준 편차(σ)를 사용하여 정의된다.
- latent variable은 표준 정규 분포에서 샘플링된다.
- 오토인코더는 인풋과 아웃풋이 항상 같도록 하는 것이 목적이라면, VAE는 그렇지 않기 때문에 노이즈를 샘플링하여 이를 통해 잠재 변수를 만든다.
- 오토인코더에서 잠재 변수가 하나의 값이라면, VAE에서의 잠재 변수는 가우시안 확률 분포에 기반한 확률값
- 디코더 (Decoder)
- 디코더는 잠재 변수 z를 입력으로 받아 원래의 데이터 x를 복원하는 역할을 수행
- 디코더는 잠재 변수로부터 생성된 데이터의 분포를 학습
- 잠재 변수를 입력으로 받아, 디코더는 잠재 변수에서 원래 입력 데이터를 생성하는 분포의 매개변수를 출력
- 재구성 손실 (Reconstruction Loss):
- VAE의 학습은 재구성 손실을 최소화하도록 이루어 짐
- 재구성 손실은 디코더가 잠재 변수를 사용하여 입력 데이터를 얼마나 잘 재구성하는지를 측정
- 이 손실은 주로 평균 제곱 오차(Mean Squared Error)나 교차 엔트로피 손실(Cross-Entropy Loss)로 계산 됨
- KL 발산 (KL Divergence)
- VAE에서는 잠재 변수의 분포가 표준 정규 분포와 유사하도록 유도하는 추가적인 항인 KL divergence가 존재
- 이 항은 모델이 학습된 분포와 원래의 정규 분포 간의 차이를 측정하고, latent variable이 고르게 분포하도록 한다.
# VAE 모델 pytorch 코드 예시
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
from torch.autograd import Variable
# VAE 모델 정의
class VAE(nn.Module):
def __init__(self, input_size, hidden_size, latent_size):
super(VAE, self).__init__()
# 인코더 정의
self.encoder = nn.Sequential(
nn.Linear(input_size, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, latent_size * 2) # mu와 logvar을 동시에 출력
)
# 디코더 정의
self.decoder = nn.Sequential(
nn.Linear(latent_size, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, input_size),
nn.Sigmoid() # 이미지 생성을 위해 Sigmoid 사용
)
def reparameterize(self, mu, logvar):
std = torch.exp(0.5 * logvar)
eps = torch.randn_like(std)
return mu + eps * std
def forward(self, x):
# 인코더를 통해 mu와 logvar 계산
enc_output = self.encoder(x)
mu, logvar = enc_output[:, :latent_size], enc_output[:, latent_size:]
# 리파라미터화 트릭을 사용하여 잠재 변수 샘플링
z = self.reparameterize(mu, logvar)
# 디코더를 통해 잠재 변수로부터 이미지 생성
recon_x = self.decoder(z)
return recon_x, mu, logvar- 주목할 만한 부분은 latent vector의 리파라미터화(reparameterization) 과정으로 평균(mu)과 로그 분산(logvar)을 사용하여 latent vector를 샘플링
- std = torch.exp(0.5 * logvar) : 로그 분산으로 표준 편차를 계산
- eps = torch.randn_like(std) : 표준 정규 분포에서 샘플링된 랜덤 노이즈를 생성. torch.randn_like() 함수는 주어진 텐서와 같은 크기의 표준 정규 분포에서 샘플링된 랜덤값을 생성 함
- mu + eps * std : 최종적으로 latent vector를 계산. 이렇게 구한 latent vector는 디코더의 입력으로 사용
# VAE Loss 계산
# Loss 계산
BCE = criterion(recon_data, data)
KLD = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp())
loss = BCE + KLDVAE의 loss는 Reconstruction loss와 KL divergence로 구성
전체 손실은 재구성 손실과 KL 발산의 합으로 구성 → loss = BCE + KLD.
1. Reconstruction Loss
- criterion = nn.BCELoss(reduction='sum'): 여기서는 이진 교차 엔트로피 손실 함수를 사용하고, 'sum' reduction을 선택 (모든 픽셀에 대한 loss의 합계를 구하는 방식)
- BCE = criterion(recon_data, data): Reconstruction Loss는 생성된(recon_data) 이미지와 원본(data) 이미지 간의 이진 교차 엔트로피를 측정
- 목표는 생성된 이미지가 원본 이미지와 유사하게 되도록 하는 것
2. KL Divergence Loss
- KLD = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp()): KL 발산은 latent variable의 분포가 정규 분포와 얼마나 차이나는지를 측정
- 식에서 mu는 인코더에서 나온 latent variable의 평균, logvar는 로그 분산
- 이 부분은 VAE의 핵심이며, 모델이 latent variable를 표준 정규 분포에 가깝게 유도하도록 한다.
- 이는 모델이 훈련 중에 더 안정적으로 학습되도록 한다.
반응형
'🏛 Research > Generative AI' 카테고리의 다른 글
| [Gen AI] Diffusion Model과 DDPM 개념 설명 (0) | 2025.03.31 |
|---|---|
| [논문 리뷰] DREAMFUSION: TEXT-TO-3D USING 2D DIFFUSION (0) | 2025.03.23 |
| [논문 리뷰] Zero-1-to-3: Zero-shot One Image to 3D Object | Single-view object reconstruction (0) | 2025.03.22 |
| [Gen AI] Stable Diffusion: 이미지 생성 AI 이해하기 (0) | 2024.11.04 |
| [기술 소개] Text-to-Image Generation | 이미지 생성 AI | DALL-E | GPT | dVAE (0) | 2023.04.06 |