1. Intro
Goku는 단순히 아카데믹한 논문이 아니라, 프로덕션 레벨의 joint image/video generative foundation model을 실제로 학습·운영하기 위해 필요한 구성요소(토크나이저, 아키텍처, 데이터 큐레이션, 분산 학습 시스템)를 한 번에 정리한 설계 제안에 가깝다.비디오 생성에서 병목은 크게 세 가지로 정리된다.
- 표현 병목: 시간축이 추가되면서 scene transition, camera motion, action dynamics 등 장면의 변화 양상이 급격히 복잡해진다.
- 데이터 병목: 대규모 video-text 페어는 노이즈, 워터마크, 저품질 샘플, 분포 편향이 심하며, 결과적으로 큐레이션 품질이 모델 성능을 좌우한다.
- 시스템 병목: 비디오 토큰은 시퀀스 길이가 매우 길어지므로, full-attention 기반 학습을 하려면 sequence parallelism, sharding, checkpointing, fault tolerance 같은 대규모 분산 학습 인프라가 사실상 필수 조건이 된다.
2. Goku: Generative Flow Models for Visual Creation
Goku는 (1) Image-Video Joint VAE 토크나이저, (2) 텍스트 인코더(Flan-T5), (3) Rectified Flow(RF) 기반 video/image Transformer로 구성된다.
┌───────────────────────────────┐
│ Text Prompt │
└───────────────┬───────────────┘
│
▼
┌───────────────────┐
│ Flan-T5 Encoder │
│ (text embeddings) │
└─────────┬─────────┘
│ (used as cross-attn cond)
▼
============================= TRAINING (Rectified Flow) =============================
┌───────────────────────┐
│ Image / Video Pixels │
└───────────┬───────────┘
│
▼
┌───────────────────────────────┐
│ Image-Video Joint VAE Encoder │
│ - image stride: 8×8 │
│ - video stride: 8×8×4 │
└───────────┬───────────────────┘
│
▼
latent target x1
│
├───────────────┐
│ │
│ sample x0 ~ N(0, I)
│ │
└───────┬───────┘
▼
RF interpolation (t ∈ [0,1]):
x_t = t·x1 + (1-t)·x0
│
▼
┌───────────────────────────────────────────────┐
│ Goku Transformer │
│ - full attention + 3D RoPE │
│ - Patch n' Pack (sequence packing) │
│ - QK-Norm, adaLN-Zero (t-conditioning) │
│ - cross-attention to Flan-T5 embeddings │
└───────────┬───────────────────────────────────┘
│
▼
predict velocity v̂(x_t, t, text)
│
▼
loss: || v̂ - v ||² (velocity regression in latent)
============================== INFERENCE (Sampling) ================================
sample latent x0 ~ N(0, I)
│
▼
integrate / sample in latent space (ODE solve / RF sampling)
with text conditioning via Flan-T5 (cross-attn)
│
▼
generated latent x1*
│
▼
┌───────────────────────────────┐
│ Image-Video Joint VAE Decoder │
└───────────┬───────────────────┘
│
▼
generated image / video pixels
2.1 Tokenizer: Image-Video Joint VAE
Transformer 기반 생성에서 비용은 토큰 길이가 결정된다. Goku는 이미지와 비디오를 동일한 latent space로 압축하는 Image-Video Joint VAE를 사용해 T2I/T2V/I2V를 동일 프레임워크로 통합한다.
압축 규격(Stride)
- Image: spatial stride 8×8
- Video: spatial-temporal stride 8×8×4
즉, 비디오는 시간축도 함께 다운샘플링하여 토큰 수(=attention 비용)를 제어한다.
설계 해석
- Joint VAE는 생성 품질의 상한을 만든다.
- temporal stride(×4) 압축은 모션 디테일을 희생할 수 있으므로, 이후 아래 요소로 보완한다.
- (a) full-attention 기반 시간 모델링으로 long-range temporal dependency를 직접 학습
- (b) motion score 기반 필터링으로 학습하기 쉬운 모션 분포를 확보
- (c) motion score를 캡션에 주입해 텍스트 조건에서 모션 제어 신호를 강화
2.2 Model Architecture
2.2.1 블록 구성
Goku는 conditional Transformer 블록을 사용한다.
- Self-Attention: latent 토큰 간 상호작용
- Cross-Attention: 텍스트 컨디션(Flan-T5 embedding) 주입
- FFN
- adaLN-Zero: t(또는 timestep) 기반 안정적 conditioning
2.2.2 Full-Attention 선택의 의미
비디오 Transformer는 비용 때문에 temporal/spatial attention을 분해하거나 factorization하는 경우가 많다. Goku는 motion + long-range dependency를 강하게 모델링하기 위해 plain full-attention을 택한다.
- 장점: 모션 전개, 카메라 이동, 장면 내 객체 상호작용을 단순화 없이 학습 가능
- 비용: 시퀀스 길이가 폭증하므로 FlashAttention + (SP/FSDP) + activation checkpointing이 전제된다.
2.2.3 3D RoPE(Position Encoding)
이미지·비디오 토큰에 3D RoPE(공간+시간)를 적용한다.
- 다양한 해상도/길이에 대해 RoPE의 extrapolation 성질을 활용한다.
- joint 학습에서 해상도 스테이지가 바뀌는 커리큘럼에서도 안정적으로 동작하도록 설계된 선택으로 해석된다.
2.2.4 Patch n’ Pack(Sequence Packing)
Goku는 NaViT 계열의 packing을 적용해, 서로 다른 길이·해상도의 이미지/비디오 샘플을 하나의 긴 시퀀스로 패킹해 minibatch를 구성한다. 목적은 길이/해상도별 버킷과 과도한 padding을 피하고 GPU utilization을 올리는 것이다.
핵심은 두 가지이다.
- Concatenate: 서로 다른 샘플의 토큰을 시퀀스 축으로 이어붙인다.
- Block-diagonal attention mask: 서로 다른 샘플 간 토큰이 attention하지 않도록 차단한다.
예를 들어,
- image latent length = 1,024
- video-A latent length = 4,096
- video-B latent length = 3,072
패딩 방식이라면 max=4,096에 맞춰 image는 3,072 토큰이 낭비된다. Patch n’ Pack은 다음처럼 만든다.
- packed length = 1,024 + 4,096 + 3,072 = 8,192
- attention mask는 아래처럼 블록만 활성화된다
[ image ][ video-A ][ video-B ]
|██████|........|........|
|......|████████|........|
|......|........|████████|
추가적으로,
- packing을 하면 글로벌 시퀀스 인덱스의 의미가 약해지므로, 각 토큰에 대해 (t, h, w) 좌표를 유지하고 3D RoPE를 좌표 기반으로 계산하는 방식이 자연스럽다.
- stage-2에서 이미지/비디오를 같은 batch에 섞을 때, packing은 이미지/비디오 비율을 유연하게 조절하면서도 padding 손실을 줄인다.
2.2.5 Q-K Normalization(QK-norm)
대규모 Transformer 학습에서 간헐적으로 발생하는 loss spike를 완화하기 위해, attention dot-product 이전에 q와 k에 normalization을 적용한다.
- 방식: q <- RMSNorm(q), k <- RMSNorm(k) 후 softmax(q k^T / sqrt(d))
- 직관: q·k의 스케일 폭주를 제한해 softmax 입력 분산을 안정화한다.
조금 더 기술적으로 보면, q와 k를 정규화하면 attention logit은 내적이라기보다 코사인 유사도 성격에 가까워진다.
- 정규화가 없으면: logit = ||q||·||k||·cos(θ)
- 정규화 후에는: logit ≈ cos(θ) (스케일 항이 크게 줄어듦)
즉, 특정 토큰/헤드에서 ||q|| 또는 ||k||가 비정상적으로 커져 softmax가 한쪽으로 쏠리는 현상을 완화하고 학습을 더 안정적으로 만든다.
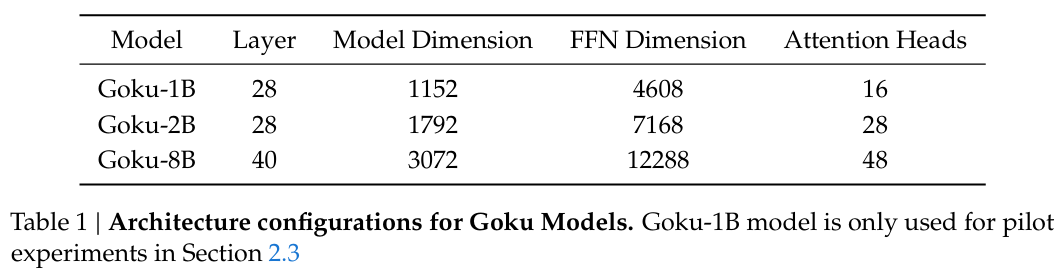
2.2.6 모델 스케일
2.3 Flow-Matching Training (Rectified Flow)
Goku의 학습은 rectified flow(RF) 기반 flow formulation에 뿌리를 둔다. 핵심은 prior에서 시작해 target data 분포로 샘플을 연속적으로 이동시키는 velocity field를 학습하는 것이다. 학습 샘플은 linear interpolation으로 구성된다.
- target(데이터) 샘플: x1
- prior(노이즈) 샘플: x0 ~ N(0, I)
- 보간 계수: t ∈ [0, 1]
x_t = t · x1 + (1 - t) · x0
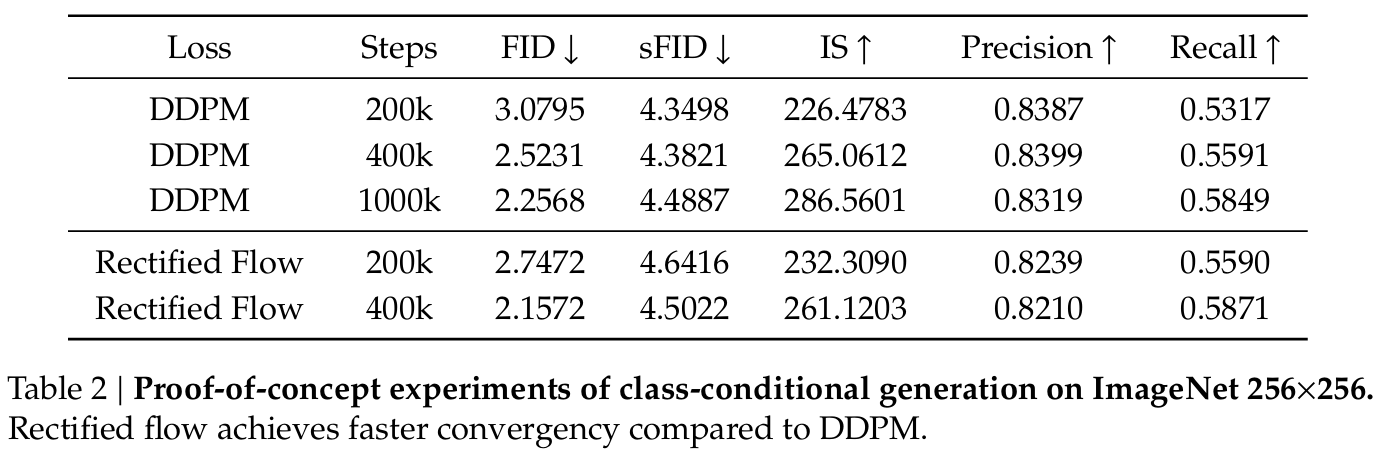
모델은 x_t를 입력받아 velocity v_t = d x_t / d t 를 예측하도록 학습된다. 구현 관점에서는 “RF objective로 latent에서 velocity regression을 L2로 맞춘다”로 이해하면 된다. 논문은 pilot experiment로 ImageNet-1K(256×256) class-conditional 설정에서 DDPM 대비 RF가 더 빠른 수렴을 보인다고 한다. 구체적으로, Goku-1B(RF)는 약 400k step에서 DDPM이 1000k step 수준에서 도달하는 성능대(예: FID-50K)에 더 빨리 접근한다. 인퍼런스는 latent에서 ODE solve(또는 RF sampling 절차)에 해당하며, 얻어진 latent를 Joint VAE decoder로 복원해 픽셀 공간의 이미지/비디오를 생성한다.
2.4 Training Details
모델 학습의 핵심은 (1) multi-stage curriculum, (2) cascaded resolution, (3) long-seq 학습을 가능하게 하는 병렬화·체크포인팅·fault tolerance이다.
2.4.1 Multi-stage Training
논문은 joint image-and-video 학습을 한 번에 직접 최적화하기 어렵다고 전제하고, 아래 3단계로 분해한다.
- Stage-1: Text–Semantic Pairing
- text-to-image 중심 pretraining으로 텍스트-시각 의미 매핑을 먼저 안정화한다.
- object attributes, spatial configuration, contextual coherence 같은 “정적 시각 개념”을 우선 학습하는 단계이다.
- Stage-2: Image-and-Video Joint Learning
- 이미지와 비디오를 unified token sequence로 통합해 joint 학습한다.
- 고품질 비디오 데이터 확보가 상대적으로 어렵기 때문에, 고품질 이미지가 가진 풍부한 시각 정보를 joint 학습에서 비디오로 전이시키는 설계를 강조한다.
- Stage-3: Modality-specific Finetuning
- 최종 단계에서 모달리티별로 분리해 미세조정한다.
- T2I는 image-centric adjustment로 “더 보기 좋은 이미지” 방향을 목표로 한다.
- T2V는 temporal smoothness, motion continuity, stability 개선에 초점을 둔다.
2.4.2 Cascaded Resolution Training
논문은 Stage-2의 joint training에서 cascade resolution을 적용한다.
- 초기: 288×512(low-res)에서 text–semantic–motion의 핵심 상호작용을 저비용으로 먼저 학습한다.
- 이후: 480×864 → 720×1280로 단계적으로 해상도를 상승시켜 디테일과 fidelity를 정련한다.
2.4.3 Efficiency & Long-seq Training System
Goku는 VAE 이후에도 비디오 토큰 수가 매우 크며, 논문은 longest sequence가 220K tokens를 초과한다고 명시한다. 이를 위해 3D parallelism(시퀀스/데이터/파라미터 축)을 사용하고, 구성 요소를 아래처럼 제시한다.
- FlashAttention + Sequence Parallelism
- full-attention 채택에 따른 메모리/연산 부담을 완화하기 위해 FlashAttention과 sequence parallelism을 사용한다.
- Sequence-Parallelism (Ulysses 구현)
- 시퀀스 차원으로 샘플을 sharding한다.
- attention 계산 시 all-to-all로 Q/K/V shard를 분배해 각 워커가 full sequence를 처리하되 head subset만 담당하도록 구성한다.
- 계산 후 all-to-all로 결과를 다시 집계해 head 및 시퀀스 차원을 재결합한다.
- FSDP with HYBRID_SHARD
- 파라미터/그래디언트/옵티마 상태를 sharding한다.
- HYBRID_SHARD(FULL_SHARD + group 간 replication)로 all-gather/reduce-scatter 범위를 줄여 통신 비용을 낮춘다고 설명한다.
- Fine-grained Activation Checkpointing
- 통신 오버헤드와 compute를 균형 있게 만들기 위해 selective / fine-grained AC를 설계한다.
- 저장이 필요한 activation을 최소화하면서 GPU utilization을 최대화하는 쪽에 초점을 둔다.
- Cluster Fault Tolerance (MegaScale)
- 대규모 클러스터에서 node failure 가능성이 높아지는 점을 전제로 self-check diagnostics, multi-level monitoring, fast restart/recovery를 도입한다.
- Saving/Loading: ByteCheckpoint
- checkpoint에는 model parameters뿐 아니라 EMA parameters, optimizer states, random states까지 포함한다.
- ByteCheckpoint를 사용해 partitioned checkpoint를 병렬 저장/로드하고, resharding까지 지원해 training scale 전환을 유연하게 만든다.
- 논문은 8B 모델을 수천 GPU에서 checkpoint할 때 training block이 4초 미만이라고 보고한다.
3. Infrastructure Optimization
Goku는 “모델이 크다”보다도, 비디오 latent token이 만들어내는 긴 시퀀스가 병목이다. 논문은 longest sequence가 220K tokens를 초과한다고 명시하며, 이를 전제로 3D parallelism(시퀀스/데이터/파라미터 축), fine-grained activation checkpointing, 클러스터 fault tolerance, 고성능 체크포인팅(ByteCheckpoint)를 결합해 학습을 성립시킨다.
간단히 표현하면 아래 구조이다.
[Sequence axis] Ulysses Sequence Parallelism (all-to-all for Q/K/V shards)
[Data axis] Data Parallel groups (replicated compute)
[Param axis] FSDP HYBRID_SHARD (FULL_SHARD within shard-group)
+ Fine-grained Activation Checkpointing
+ MegaScale Fault Tolerance
+ ByteCheckpoint (parallel save/load + resharding)3.1 Model Parallelism Strategies: 3D Parallelism으로 220K-token을 버틴다
논문은 모델 크기와 시퀀스 길이(>220K tokens)가 동시에 커지므로, 단일 병렬화 축으로는 학습이 불가능하다고 전제한다. 이에 input sequence / data / model parameters의 3개 축으로 확장되는 3D parallelism을 사용한다.
3.1.1 Sequence Parallelism(SP)
Sequence-Parallelism은 입력을 sequence dimension으로 sharding한다. LayerNorm 같은 independent layer에서 불필요한 중복 계산을 제거하고, 메모리 사용량을 줄이며, non-conforming input(길이/패딩이 다른 샘플)에 대한 처리를 용이하게 한다. 논문은 구현으로 Ulysses를 사용한다.
- 학습 루프 시작부터 샘플을 sequence-parallel group에 sharding한다.
- attention 계산 시 all-to-all로 Q/K/V shard를 재분배하여,
- 각 워커가 “full sequence”를 처리하되
- “attention head의 subset”만 담당하도록 만든다.
- head-wise attention을 병렬로 계산한 뒤, 또 한 번의 all-to-all로 결과를 집계해 head와 sharded sequence 차원을 재결합한다.
즉, SP는 “시퀀스가 너무 길어도 attention을 full-attention으로 유지”하기 위한 전제 조건으로 사용된다.
3.1.2 FSDP
논문은 데이터 병렬 대신 FSDP(Fully Sharded Data Parallelism)를 사용한다. Goku는 특히 HYBRID_SHARD 전략을 사용한다.
- shard group 내부는 FULL_SHARD로 파라미터를 샤딩하고,
- shard group 간에는 파라미터를 복제하여 “효과적으로 DP”를 구현한다.
- 결과적으로 all-gather/reduce-scatter의 범위를 shard group 내부로 제한해 통신 비용을 낮춘다.
일반적으로 HSDP(= Hybrid Sharded Data Parallel)라 불리는 전략이다.
3.2 Activation Checkpointing
논문은 3.1의 병렬화가 메모리를 크게 절약하지만, rank 간 통신이 늘어나 전체 성능이 비선형적으로 떨어질 수 있음을 지적한다. 이를 완화하기 위해 fine-grained Activation Checkpointing(AC)를 설계한다.
핵심은 “무조건 전부 checkpoint”가 아니라, 프로파일링 관점에서 compute와 communication의 overlap을 최대화하도록
- activation 저장이 필요한 레이어 수를 줄이고
- GPU utilization을 최대화하는 방향으로
- selective checkpointing을 적용한 것이다.
3.3 Cluster Fault Tolerance
대규모 GPU 클러스터에서 학습할수록 node failure 확률이 증가하고, 이는 학습 효율(시간/비용)을 직접 악화시킨다. 논문은 이를 전제로 MegaScale의 fault tolerance 기법을 채택한다.
- self-check diagnostics
- multi-level monitoring
- fast restart / recovery
목표는 장애를 없애는 것이 아니라, 장애가 발생해도 학습 중단 시간을 최소화하고 전체 시스템이 안정적으로 지속되도록 만드는 것이다.
3.4 Saving and Loading Training Stages
대규모 학습에서는 checkpoint가 단순 백업이 아니라 운영 요소이다. 논문은 checkpoint에 다음 상태를 포함한다고 명시한다.
- model parameters
- EMA parameters
- optimizer states
- random states
이는 (1) 클러스터 fault 가능성이 높아지는 환경에서 재시작을 가능하게 하고, (2) 재현성을 보장하며, (3) 디버깅(비의도적 버그, 악의적 공격 포함) 관점에서도 중요하다.
이를 위해 ByteCheckpoint를 채택한다.
- partitioned checkpoint를 병렬 저장/로드(high I/O efficiency)
- distributed checkpoint를 resharding 지원
- rank 수와 storage backend가 달라져도 training scale 전환을 유연하게 처리
논문은 경험적으로, 8B 모델을 수천 GPU에서 checkpoint할 때 training block이 4초 미만이라고 보고한다.
4. Data Curation Pipeline

Goku 논문에서는 데이터 큐레이션 파이프라인을 5단계로 정리한다.
- image/video collection
- video extraction & clipping
- image/video filtering
- captioning
- data distribution balancing
4.1 Data Overview
논문은 raw 데이터를 public academic dataset + internet resources + proprietary(파트너십 기반)로부터 수집하고, rigorous filtering 이후 최종 학습 세트를 다음과 같이 제시한다.
세부 구성은 다음과 같다.
- Text-to-Image
- public 100M: LAION
- internal 60M: 고품질 사내 데이터
- 논문은 “public data로 pre-training, internal data로 fine-tuning” 전략을 명시한다.
- 최종 학습 데이터: 160M image-text pairs
- Text-to-Video
- public 11M clips + in-house 25M clips
- public 원천에는 Panda-70M, InternVid, OpenVid-1M, Pexels가 포함된다.
- 단, “그대로 사용”이 아니라 동일한 큐레이션 파이프라인을 적용해 고품질 샘플만 남긴다.
- 최종 학습 데이터: 36M video-text pairs
4.2 Data Processing and Filtering
비디오 데이터는 단순 수집만으로는 학습에 적합하지 않다. 논문은 품질을 좌우하는 전처리/클리핑/필터링을 단계적으로 적용한다.
4.2.1 Preprocessing & Standardization

인터넷 영상은 인코딩/길이/FPS/비트레이트가 제각각이다. 논문은 먼저 계산적으로 저렴한 1차 필터링을 수행하고, 이후 인코딩을 H.264로 통일한다. 항목별 threshold는 위 table 3 와 같다. 이 단계는 aesthetic model 같은 고비용 필터링보다 먼저 적용되어 전체 파이프라인 비용을 절감한다.

4.2.2 Video Clips Extraction
논문은 2-stage clipping을 사용한다.
- PySceneDetect로 shot boundary detection을 수행해 coarse clip을 만든다.
- coarse clip 내부에서 1fps로 프레임을 샘플링하고, 각 프레임의 DINOv2 feature를 구한 뒤 인접 프레임 cosine similarity를 계산한다.
- similarity가 임계값 아래로 내려가면 shot change로 간주해 clip을 추가 분할한다
해상도별 DINO similarity threshold 수치는 위 Table 4에 정리되어 있다. 추가로, clip 길이는 최대 10초로 제한한다.
4.2.3 Clip Diversity
같은 source video에서 나온 clip들이 유사하면 데이터 다양성이 무너진다. 논문은 각 clip의 keyframe에 대해 perceptual hashing을 계산하고, 두 clip의 hash가 유사(중복 가능성 높음)하면 aesthetic score가 더 높은 clip을 유지한다.
4.2.4 Visual Aesthetic Filtering
논문은 keyframe에 대해 aesthetic model score를 구해 평균을 취하고, 해상도별 threshold로 low-quality clip을 제거한다.
4.2.5 OCR Filtering
워터마크/자막 중심 영상은 생성 품질과 분포를 망가뜨릴 수 있다. 논문은 internal OCR로 keyframe의 텍스트를 검출하고, keyframe 내 가장 큰 text bbox 면적 / keyframe 전체 면적을 text coverage ratio로 정의한다. threshold는 해상도별로 다르게 둔다.
4.2.6 Motion Filtering: RAFT optical flow 기반 motion score
비디오는 “얼마나 움직이느냐”가 데이터 품질과 학습 난이도를 좌우한다. 논문은 RAFT로 mean optical flow를 계산하고 motion score를 도출한다. 추가로, motion control 강화를 위해 motion score를 caption에 append한다.
4.2.7 Multi-level Training Data(해상도 스테이지별 데이터 양)
논문은 해상도/필터링 강도를 올릴수록 데이터 양이 줄어드는 multi-level 구성을 명시한다(Table 4).
각 레벨은 Resolution + DINO-sim + aesthetic + OCR + motion score의 threshold 조합으로 정의된다.
4.3 Captioning
Goku는 dense caption을 전제로 텍스트-비주얼 정합을 강화한다.
- Images: InternVL2.0으로 각 이미지에 dense caption을 생성한다.
- Videos:
- InternVL2.0으로 keyframe caption 생성
- Tarsier2로 video-wide caption 생성
- Tarsier2는 camera motion type(zoom in, pan right 등)을 자연스럽게 기술할 수 있어 별도 motion-type predictor가 필요 없다고 설명한다.
- Qwen2로 keyframe caption과 video-wide caption을 merge해 최종 캡션을 만든다.
- RAFT 기반 motion score를 캡션에 추가해, 프롬프트에서 motion score를 지정하는 형태의 motion controllability를 강화한다.
4.4 Training Data Balancing

논문은 “비디오 데이터 분포”가 성능에 큰 영향을 준다고 전제한다. 이를 위해 internal video classification model로 semantic tag를 생성하고, tag 분포를 기반으로 데이터 분포를 재조정한다.
- semantic tag 생성: 4개의 evenly sampled keyframe을 사용해 분류
- 분류 체계: 9개 primary class(예: human, scenery, animals, food 등) + 86개 subcategory(예: half-selfie, kid, dinner, wedding 등)
- 관측된 분포: humans/scenery/food/urban life/animals가 상대적으로 우세
Balancing 전략은 다음을 목표로 한다.
- human 관련 콘텐츠는 appearance diversity가 크고 모델링 난도가 높으므로 human 비중을 상대적으로 강조한다.
- 동시에 각 primary category 내부에서 subcategory가 치우치지 않도록 equitable representation을 보장한다.
구체적 조정 방식은 다음으로 기술된다.
- overrepresented subcategory: selective down-sampling
- underrepresented subcategory: artificial data generation + oversampling
이 과정을 통해 Figure 3b와 같은 균형 분포를 얻는다고 설명한다.
5. Experiments
논문은 Goku를 T2I / T2V / I2V 관점에서 평가하며, 정량 벤치마크와 정성 비교 + ablation으로 구성한다. 이 절은 수치 해석에 필요한 포인트만 간소화해 정리한다.
5.1 Text-to-Image (T2I)
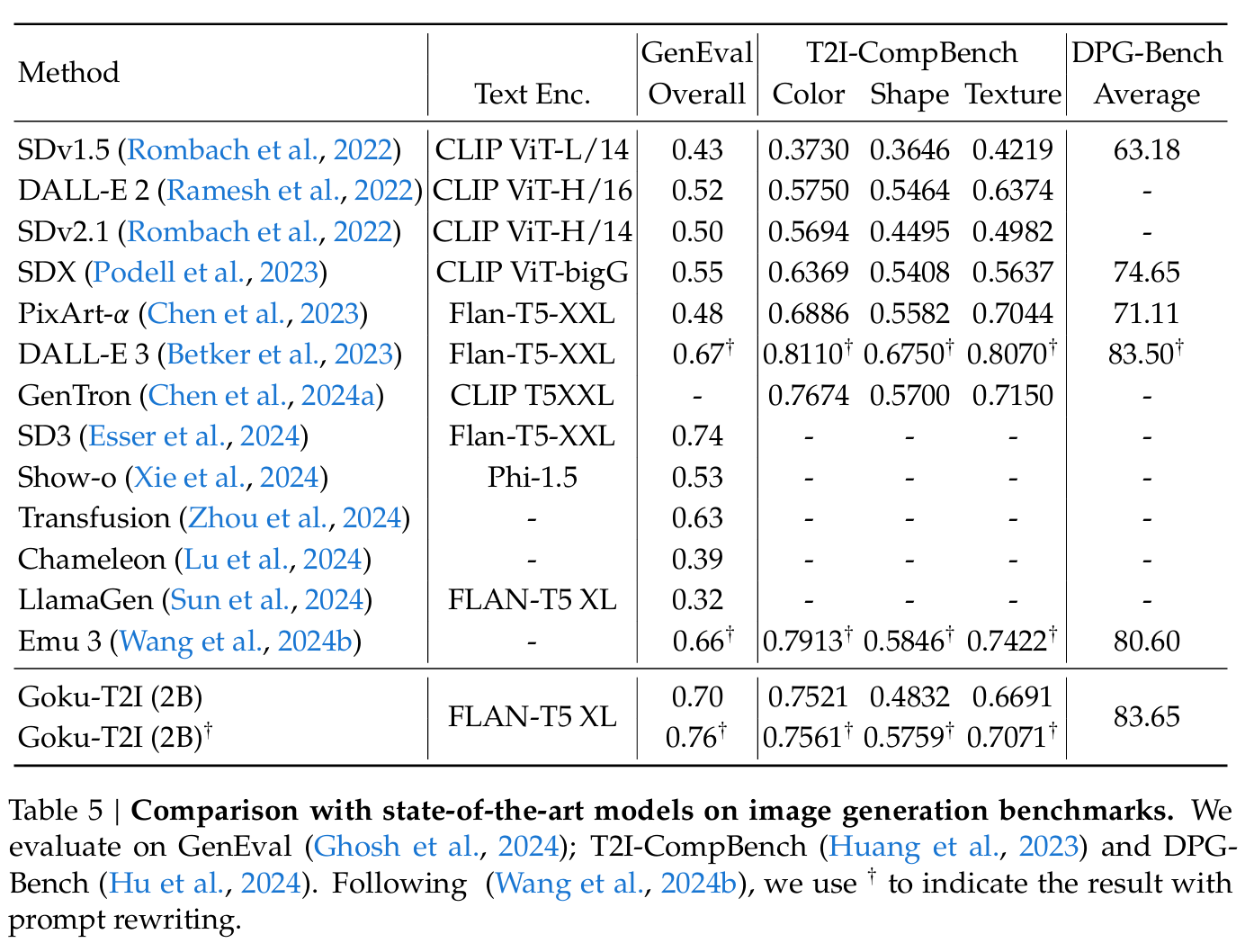
Goku-T2I는 dense generative caption 중심 학습을 전제로, text-image alignment을 강하게 강조한다.
- GenEval: 원본(short prompt)과, 원본 의미를 유지한 채 더 상세하게 확장한 rewritten prompt(논문에서는 ChatGPT-4o를 사용)를 모두 평가한다.
- Goku-T2I(2B)는 원본 프롬프트에서도 강한 점수를 보이며, rewritten prompt에서는 0.76로 최고 성능을 보고한다.
- 이 결과는 “상세 프롬프트에 강한 caption-centric 학습”이 실제 alignment 지표에서 이점을 준다는 해석과 맞물린다.
- T2I-CompBench / DPG-Bench: 색/형태/텍스처 같은 조합적 속성(comp. attributes)과 사람 선호 기반 품질(또는 프롬프트-이미지 정합)을 함께 본다.
- Table 5에서 Goku-T2I(2B)는 T2I-CompBench의 color/shape/texture 축에서 경쟁력 있는 수치를 보이고, DPG-Bench에서 83.65를 보고한다(표 내 평균 점수).
요약하면, T2I 실험 파트의 메시지는 “RF objective 자체”보다 (a) dense caption 기반 학습, (b) 세밀한 prompt에서의 정합 우위이다.
5.2 Text-to-Video (T2V)


- UCF-101 zero-shot (FVD↓ / IS↑)
- Table 6에서 Goku-2B는 256×256 기준 FVD 246.17 / IS 45.77(±1.10)을 보여준다.
- 동일 모델을 서로 다른 해상도(240×360, 128×128)로 생성했을 때의 수치도 함께 제시하며, 해상도/토큰 길이/학습 안정성과의 trade-off를 간접적으로 보여준다.
- VBench (16D 평가의 요약치)
- Table 7에서 Goku(ours)는 Overall 84.85로 비교 대상 중 최고 성능을 보고한다.
- Quality score 85.60, Semantic score 81.87을 함께 제시하며, 단순 화질뿐 아니라 의미 정합과 동적 표현(예: multiple objects, dynamic degree 등)까지 균형 있게 끌어올렸다는 메시지를 강조한다.
- 정성 비교
- 공개 모델(CogVideoX, Open-Sora-Plan 등)과 상용 제품(Pika, DreamMachine, Vidu, Kling v1.5 등)을 함께 비교한다.
- 논문은 복잡 프롬프트에서 일부 상용 모델이 핵심 요소를 누락하거나(예: 특정 객체/구성 실패), 모션 일관성이 깨지는 사례를 언급하며, Goku-8B가 세부 요소 반영과 모션 일관성에서 우수함을 강조한다.
5.3 Image-to-Video (I2V)

I2V는 T2V를 학습한 뒤, reference image conditioning을 추가하는 방식으로 확장한다.
- T2V initialization에서 출발해, 약 4.5M text-image-video triplet로 finetune한다.
- finetuning step은 10k로 비교적 짧게 설정되지만, reference image의 정체성을 유지하면서 텍스트 조건에 맞는 모션을 생성하는 능력을 보여준다고 정리한다.
5.4 Ablation

논문은 아래 두 축을 간단히 ablation한다.
- Model scaling (2B → 8B): 파라미터를 늘리면, 왜곡된 구조(팔, 바퀴 등) 같은 “local geometry artifact”가 완화되는 경향을 제시한다.
- Joint training 유무: 동일한 pretrained Goku-T2I(8B)에서 출발해, 동일 step으로 480p 비디오를 finetune할 때
- joint image+video training이 없으면 프레임 품질이 떨어지거나 photorealism이 깨지기 쉽고,
- joint training을 포함하면 photorealistic frame이 더 안정적으로 유지된다고 보고한다.
Goku의 핵심 기여는 “RF로 비디오를 만든다”가 아니라, 현실적인 스케일에서 T2V/I2V 모델을 학습 가능한 형태로 패키징했다는 점이다. 현시점에서 시사점은 크게 세 가지로 정리된다.
- 비디오 생성은 알고리즘보다 ‘데이터+시스템’의 문제로 수렴하고 있다.
- longest sequence >220K tokens 같은 설정에서 full-attention을 유지하려면, SP/FSDP/AC/체크포인트/장애 복구가 알고리즘의 일부가 된다.
- 모델 아키텍처만 복제해서는 재현이 안 되고, 학습 인프라 설계가 성능의 실질적 결정 요인이 된다.
- 큐레이션이 곧 성능이고, 큐레이션이 곧 커리큘럼이다.
- Table 3/4처럼 해상도 단계별로 DINO similarity/aesthetic/OCR/motion threshold를 명시적으로 설계하고, 그 결과 36M→24M→7M으로 데이터가 정제되는 흐름 자체가 학습 커리큘럼으로 작동한다.
- 특히 motion score 기반 필터링과 caption 주입은 “데이터 품질 제어”를 넘어 “모션 controllability”에 직접 연결되는 설계로 읽힌다.
- joint image+video 학습은 비디오 생성에서 실용적인 승부처가 된다.
- 비디오는 고품질 데이터가 항상 부족하고 분포 노이즈가 크다.
- Goku는 stage-1(T2I)로 의미를 고정하고, stage-2에서 이미지의 시각적 다양성과 품질을 비디오로 전이시키며, stage-3에서 모달리티별로 정련하는 전략을 통해 이 문제를 정면으로 다룬다.
종합하면, Goku는 “최고 성능의 단일 기법”을 제안한 논문이라기보다, 대규모 video foundation model을 만들 때 어디에 엔지니어링을 투자해야 하는지를 구체적인 수치와 파이프라인으로 보여주는 레퍼런스에 가깝다. 앞으로의 경쟁은 모델 파라미터보다, (a) long-seq 학습을 지속 가능한 비용으로 만드는 시스템, (b) 데이터 품질을 정의하고 통제하는 큐레이션 레시피, (c) 이미지·비디오를 함께 굴리는 joint 학습 설계에서 더 크게 갈릴 가능성이 높다.