NLP 분야에서 이슈가 되었던 transformer('Attention Is All You Need/NIPS2017')구조를 vision task에 접목한 Vision Transformer(ViT)와 ViT에서 개선된 구조인 Swin Transformer에 대해 설명합니다.
* 논문
A. AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE / ICLR2021
B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows / ICCV2021
1. Vision Transformer (ViT)
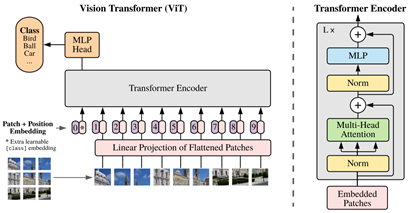
Computer vision 분야에서 기존의 self attention은 CNN 구조의 bottleneck에서 attention을 가하는 방식(Non-local network)이었지만 ViT 는 image patch의 sequence에 transformer encoder를 적용하면 이미지 분류에서 우수한 성능을 보인다는 것을 보여줍니다. 아래에서 ViT의 구조를 설명합니다.
1.1 Architecture of ViT
1.1.1 Image to Patches
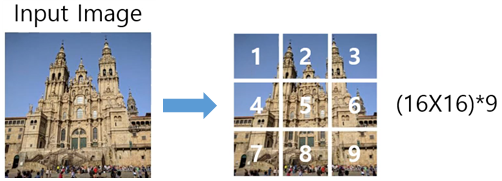
Input image를 48x48 사이즈의 RGB data로 설명합니다. Input image를 16x16 사이즈의 patch로 겹치는 부분 없이 잘라서 총 9개의 patch를 생성합니다. (x : image, xp : p*p 사이즈 patch)
1.1.2 Linear Projection
생성된 patch들은 linear projection을 통해 1-d vector로 embedding되고(16x16x3 = 768 -> 768), 이들을 patch embedding이라고 부릅니다.
1.1.3 Class token and Position embedding
Class token은 모든 patch간의 attention이 수행된 정보가 포함된 output을 출력하기 위한 수단이며, position embedding은 patch의 위치정보를 담고 있는 embedding입니다. 이들은 모두 patch embedding과 같은 차원인 768차원이며, 첫 번째 input은 class token + position embedding 이고, 나머지 input들은 각각의 patch embedding + position embedding 입니다. 때문에 예시 이미지인 48x48 사이즈의 input은 9개의 patch로 나누어지고, class token이 추가되어 총 10개의 768차원의 transformer encoder input(zlayer,sequence : z0,0,z0,1,…,z0,9 )이 준비됩니다.
1.1.4 Transformer Encoder : Multi-head Self Attention (MSA)
ViT에서는 NLP transformer와 다르게 layer normalization의 위치가 multi-head attention의 앞쪽에 위치합니다. Multi-head attention의 하나의 head에서는 input(patch embedding)에 각각의 weight를 취해 Query(Q), Key(K), Value(V) 로 embedding 시키고(768 -> 64 size) Q와 K의 dot product의 softmax로 similarity를 구하고 V를 곱해 self attention 연산을 수행합니다. Multi-head 이므로 이러한 연산을 병렬로 여러 개(현재 예시에서는 12개) 수행해서 64d * 12 = 768d의 tensor가 출력되므로 encoder의 input 사이즈와 동일합니다.
1.1.5 Transformer Encoder : MLP
이를 encoder input과 더해준 뒤에 layer normalization을 거치고 MLP(768->3072->768) 를 통과시킵니다.
이처럼 multi-head attention과 MLP를 통과했을 때 input 사이즈가 그대로 유지되게 해서 skip connection을 용이하게 했고 이러한 transformer encoder를 여러 개(현재 예시에서는 12개) 쌓아서 layer를 깊게 만듭니다.
1.1.6 MLP Head and classification
Transformer encoder layer를 12개 통과한 뒤, z12,0 (12번째 layer의 output 중 0번째 sequence / 0번째 sequence는 class token에 해당하며, 나머지 sequence는 특정 patch에 대한 embedding되므로 class token을 사용하여 이미지 전체에 해당하는 embedding을 represent합니다)를 MLP에 통과시켜 classification task를 수행합니다.
1.2 Discussion
결론적으로, ViT는 input image를 겹치지 않는 여러 개의 patch들로 나누고, 각 patch들에 position embedding을 통해 공간정보를 유지한 상태로 Multi-head Self Attention(non-local operation)을 쌓아서 classification을 수행하는 네트워크입니다.
Transformer는 CNN(CNN은 locality가 inductive bias)에 비해 inductive bias가 강하지 않아서 데이터의 양이 적은 경우에는 성능이 좋지 않습니다. 하지만, 방대한 dataset으로 pre-training하고 transfer learning 시 좋은 결과를 보여줍니다.
즉, CNN은 local한 정보가 중요하다는 점을 이용하게 되므로 여러 vision task에서 이점을 가지지만, 특정 데이터의 경우 이미지의 local한 부분보다는 global 한 context가 중요할 수도 있습니다. Transformer는 학습의 자유도가 높고 locality가 강조되는 구조가 아니기 때문에 적은 dataset으로는 학습이 힘들 수 있지만, 높은 자유도를 가지고 학습을 할 수 있기 때문에 방대한 dataset에서 더 큰 이점을 가진다고 볼 수 있습니다.
2. Swin Transformer
2.1 Introduction
앞서 설명한 ViT 는 transformer 구조를 vision task에 접목시켰지만, 이미지의 특징인 scale과 resolution의 variation이 있다는 점을 고려하지 않았고, 모든 patch들 간의 self attention을 수행해서 computation cost가 크기 때문에 vision task에 최적화된 transformer 라고 볼 수는 없습니다. 본 논문에서는 shifted window로 계산되는 representation을 가지는 hierarchical transformer인 Shifted Window Transformer(Swin Transformer)를 제안하여 ViT를 개선했습니다.

Figure 3에서 동일한 patch 사이즈만 사용되고, 이미지 전체영역에서 self attention이 계산되는 ViT에 비해, Swin Transformer 는 hierarchical한 local window와 patch를 적용하고 전체 영역이 아닌 window 안에 포함된 patch들간의 self-attention만을 계산합니다. 이러한 방식은 Inductive bias가 거의 없었던 ViT 구조에 locality inductive bias를 가해준 것으로 볼 수 있습니다. (작은 영역에서 점점 큰영역으로 self-attention을 취함)
Vision task에서 위와 같은 hierarchical한 feature를 추출하는 방식은 이미 많이 사용되고 있습니다. Object detection, segmentation에서는 서로다른 이미지의 object가 resolution과 scale이 다르지만 동일한 object일 수 있기 때문에 hierarchical한 정보가 중요합니다. 예를 들어 Feature Pyramid Network(FPN)에서는 여러 사이즈의 pooling 을 사용하여 계층적 정보를 학습합니다.

2.2 Architecture

Swin Transformer의 전체적인 구조를 보면 HxWx3 사이즈의 input image를 patch partition을 통해 겹치지 않는 4x4x3 사이즈의 patch로 분할(ViT 보다 훨씬 작은 patch 사이즈)해서 H/4xW/4x48 사이즈의 feature로 만듭니다. 이후에 ViT처럼 Linear projection을 통해 transformer encoder에 주입됩니다. Stage2부터는 stage 앞 단에 patch merging 단계가 있는데, 이는 인접한 2x2의 patch들을 하나의 patch로 합쳐서 window size가 커지더라도 window 내부의 patch 개수는 일정하게 유지합니다. 이는 patch size가 점점 커지면서 CNN처럼 hierarchical 한 정보를 학습할 수 있게 합니다. 또한 이로 인해 계산량이 선형적으로만 증가하여 ViT에 비해 계산량이 현저히 줄어들게 됩니다. (ViT 는 모든 MSA에서 모든 patch 간의 self attention을 수행하기 때문에 계산량이 많습니다.)
2.2.1 W-MSA, SW-MSA

각 Swin Transformer block은 Windows Multi-head Self Attention(W-MSA)를 수행하는 block과 Shifted Windows Multi-head Self Attention(SW-MSA)를 수행하는 block이 연속적으로 연결됩니다. W-MSA 는 local window 내부에 있는 patch들끼리만 self-attention을 수행하고, SW-MSA는 shifted된 window에서 self-attention을 수행하여 고정된 위치뿐만이 아니라 여러 영역에서의 self-attention이 수행됩니다. 위 그림의 layer1에서는 이미지 전체가 크게 4개의 window로 나누어 지고, 각 window 내부의 patch들끼리 self-attention이 수행됩니다. Layer1+1에서는 window가 shift 되므로 window 경계 때문에 self attention이 계산되지 않았던 부분들의 self attention이 수행됩니다.
2.2.2 Cyclic shift and Masked MSA
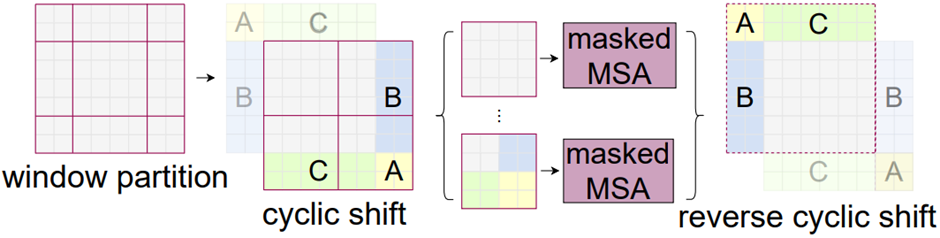
위의 예시를 기준으로 W-MSA는 4개의 window에서 self attention을 각각 수행하고, SW-MSA는 9개의 window에서 self attention을 각각 수행해야 합니다. 9개를 각각 수행 시 padding을 이용할 수 있지만 computation cost가 증가하기 때문에 본 논문에서는 ‘cyclic shift’(figure 7) 라는 방법을 사용합니다. 윈도우를 window size//2 만큼(예시에서는 2만큼) 우측 하단으로 이동시키고 좌측 상담의 A, B, C 구역을 우측하단으로 이동시킵니다. 그리고 4개로 나누어진 window 에서 각각 self attention을 수행하는데 2사분면의 window 를 제외하고는 이미지 space에서 연결된 부분이 아니기 때문에 각각 다른 mask를 씌워서 이미지 space에서 연결된 patch들간의 self attention을 수행하여 computation cost를 작게 만드는 효과를 가져옵니다. 아래 figure 8는 cyclic shift + Masked MSA의 예시입니다.

2.2.3 Relative Position Bias

Swin transformer는 ViT와 다르게 encoder 입력 부분에서 position embedding을 하지 않고 self attention을 계산하는 식에서 relative position bias(B)를 추가합니다. Position embedding은 절대 좌표였던 것이 비해 relative position bias는 patch들간의 상대좌표를 더해주는 것인데, 이것이 더 좋은 성능을 보였습니다. 아마 이미지에서 절대적인 위치 보다는 어떤 object의 part들이 있을 때 part간의 상대적인 위치가 object를 파악하는데 더 도움이 되어서 그런 것 같습니다.
2.3 Experimental Results
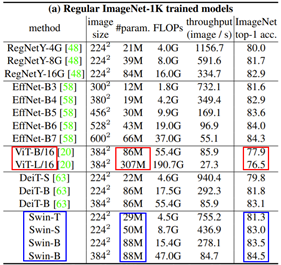
ImageNet classification 실험에서 Swin Transformer(Blue)가 ViT(Red) 보다 2배이상 작은 parameter로 성능은 3% 이상 좋은 것을 볼 수 있지만, CNN 기반의 SOTA(EffNet)보다는 성능이 낮습니다. Object detection과 segmentation task에서도 Swin transformer를 backbone으로 사용한 모델이 모든 부분에서 SOTA를 달성했습니다.

3. 내 생각
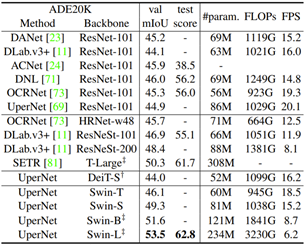
Swin Transformer는 ViT 의 문제점이었던 많은 계산량과 이미지 resolution, scale의 variation이 고려되지 않았던 점(적은 inductive bias)을 개선했고 여러 object detection, segmentation method의 backbone으로 사용할 수 있습니다. Segmentation dataset인 ADE20K의 benchmark를 보면 1~10위는 거의 모든 method가 transformer 기반이고, 현재 SOTA는 Swin Transformer version 2 입니다.

ViT는 이미지를 patch 단위로 나누고, patch 단위에서 multi-head로 non-local operation을 수행하는 구조인데, 네트워크가 깊어지더라도 처음 나뉘어진 patch를 기준으로 self attention이 수행되기 때문에 동일한 객체일지라도 이미지 space에서 shift 되는 경우에는 조금 다른 결과를 가져올 수 있을 것 같습니다. 그에 비해, Swin Transformer는 처음에는 작은 window size로 이미지를 분할하고 window 내부 patch들간의 self attention을 수행합니다. 네트워크가 깊어질수록 점점 window size와 patch size를 키워서 self attention을 수행하는데, 이는 이미지 space에서 점점 더 큰 영역(window) 내부에서 더 면적이 큰 영역(patch)간의 self attention을 수행하는 것입니다.
3.1 CNN vs. Transformer
사실 Swin Transformer의 구조와 연산은 CNN의 hierarchical한 구조와 상당히 유사하다고 생각합니다. Swin Transformer는 window, patch size를 늘려서 이미지 resolution을 줄이고, CNN은 convolutional 연산을 통해 resolution을 줄이면서 hierarchical한 representation을 생성하기 때문입니다. 때문에 CNN 구조 사이사이에 W-MSA와 SW-MSA를 삽입하면 patch merging이나 window, patch size의 변화 없이 비슷한 효과를 가져오지 않을까라는 의문이 들었습니다.
3.2 Transformer 구조의 활용
그리고 ViT는 inductive bias 가 약하기 때문에 어디에든 사용할 수 있는 도화지 같은 느낌이 들었지만, 그에 대한 단점으로 방대한 dataset으로 pre-training하지 않으면 좋은 성능을 내기 힘듭니다. Swin Transformer는 이미지의 hierarchical한 특징을 이용해서 inductive bias를 주었는데, 이처럼 여러 task에서 중요한 특징들을 ViT에 inductive bias로 활용할 수 있는 구조를 설계하면 좋은 결과를 얻을 수 있지 않을까 생각합니다.
예를 들어 texture 이미지의 경우 local structural한 특징뿐만 아니라 global statistical한 특징으로 잘 표현됩니다. 때문에 feature의 statistical한 property를 활용하는 방식으로 inductive bias를 줄 수 있다면 transformer 구조를 texture recognition에 적용해서 좋은 결과를 얻을 수 있을 것이라 생각합니다.