본 논문은 FaPN(Feature-aligned Pyramid Network)를 제안하여 ICCV2021에 게재된 논문입니다.
Motivation
대부분의 segmentation 연구에서 feature alignment 는 무시되어 왔습니다. 본 논문에서는 pixel들의 transformation offset을 학습하여 upsampling된 higher-level feature들을 상황에 맞게 align하는 feature alignment module을 제안합니다. 그리고 rich spatial detail으로 lower-feature를 강조하는 feature selection module을 제안합니다.

이게 무슨 말이나면, 위 figure의 FPN(Feature Pyramid Network)을 보면 top-down network(decoder)에서 higher-level feature와 bottom-up network의 lower-level feature를 skip connection으로 합칩니다. 이 때, higher-level feature의 spatial size를 lower-level feature와 동일하게 맞춰주기 위해 upsampling을 합니다. 이는 resolution은 낮지만 더 많이 encoding된 higher-level feature에 resolution이 더 크지만 조금 덜 encoding된 lower-level feature를 더해서 두 마리 토끼(더 많이 encoding + high resolution = 더 양질의 정보+더 정확한 위치)를 잡기 위함입니다.
그런데 단순히 higher-level feature를 upsampling해서 더해버리니까 misalingment 가 발생하여 object 의 boundary 근처에서 segmentation 정확도가 낮아지게 됩니다. 때문에 본 논문에서 이러한 단점을 커버하기 위해 top-down 과정에서 feature를 upsampling 후 재정렬을 해줘서 lower-level feature를 더했을 때 2개의 feature map 들이 정확하게 매칭되기를 바라는 것입니다.
아래 figure에서 FPN과 FaPN의 결과를 시각적으로 확인할 수 있는데, FPN에 비해 FaPN이 확실히 object의 boundary 근처에서 정확도가 높습니다.
FaPN의 전체적인 구조는 아래와 같고, FPN에서 단순히 Feature Alignment Module (FAM)과 Feature Selection Module (FSM)가 추가되었습니다. FSM으로 lower-level feature의 중요한 feature에 attention을 주고, FSM의 output과 upsampling된 higher-level feature로 feature의 misalignment를 파악하여 align 한 뒤 FSM의 output과 FAM의 output을 합쳐줍니다.
Feature Alignment Module (FAM)
FAM은 feature aggregation 전에 bottom-up feature map(C)에서 제공하는 spatial location information에 따라 upsampled feature map(P)를 재정렬하기 위한 module입니다.
구체적인 수식은 아래와 같으며, fo는 spatial difference로부터 offset을 학습하는 함수이고, fa는 학습된 offset으로 feature를 정렬하는 함수입니다.
fo와 fa 는 deformable convolution + activation + standard convolution 으로 이루어져있습니다.
deformable convolution은 kernel size의 2배 만큼(3x3 kernel 이면 9*2=18개, 위 figure에서 2N)의 channel을 만들어서 한 위치에서의 수직, 수평 offset을 학습하여 고정되지 않은 spatial 위치에서 convolution 연산을 수행하는 방법입니다. 즉 3x3 kernel이 있을때 각 9개의 위치마다 수직, 수평으로 offset이 적용된 위치의 pixel을 가져와서 연산을 수행합니다.
아래 figure의 input feature map에서 녹색 사각형들이 원래의 3x3 kernel 이고, 파랑색이 offset이 적용된 위치입니다.
FAM에서는 이러한 deformable convolution을 사용하여 bottom-up feature와 upsampled feature간의 misalignment를 offset을 학습하여 feature를 재정렬하는 것입니다. 이 때 두 feature map들을 channel 축으로 concat 하여 fo에 넣어주기 때문에(정렬해야할 두 feature map을 deformable convolution에 넣어주기 때문에) offset을 학습할 수 있게 됩니다. 그리고 fo로 학습한 offset을 이용하여 fa로 upsampled feature map을 재정렬하게 됩니다.
Feature Selection Module (FSM)
FSM은 bottom-up feature의 channel reduction(1x1 conv)를 수행하기 전에 channel-wise attention을 주기 위한 module이며 SE block 과 굉장히 흡사한데 다른 점은 위 figure에서 볼 수 있듯이 추가적인 skip connection이 있다는 점입니다.
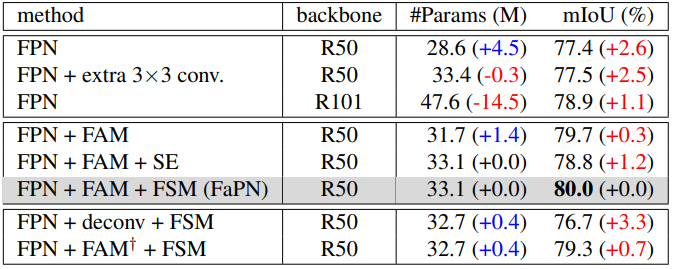
사실 SE block과 너무 흡사하고 역할도 비슷할 거 같은데, 저자는 SE block은 backbone 에서 feature extraction을 향상시키기 위해 사용되는 것이고, FSM은 top-down pathway에서 multi-scale feature aggreagation을 향상시키기 위해 사용한다고 합니다. 이렇게 말은 하지만 사실 SE랑 너무 비슷해서 그냥 SE 붙인거랑 결과는 비슷하겠지 했는데, ablation 실험을 보면 SE 대비 FSM이 mIoU가 1.2%나 높은 걸 보니 효과가 좋은 것 같습니다.
구체적인 수식은 아래와 같으며, z는 feature map을 GAP한 결과이고 fm은 1x1 conv + sigmoid 이고 fs는 1x1 conv입니다.
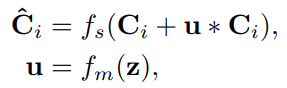
Experimental Results