CVPR 2019 에 공개된 논문으로, image classification 등의 vision 분야에서 참고하면 좋을 여러 training 방법론을 정리 및 실험한 논문입니다.
Introduction
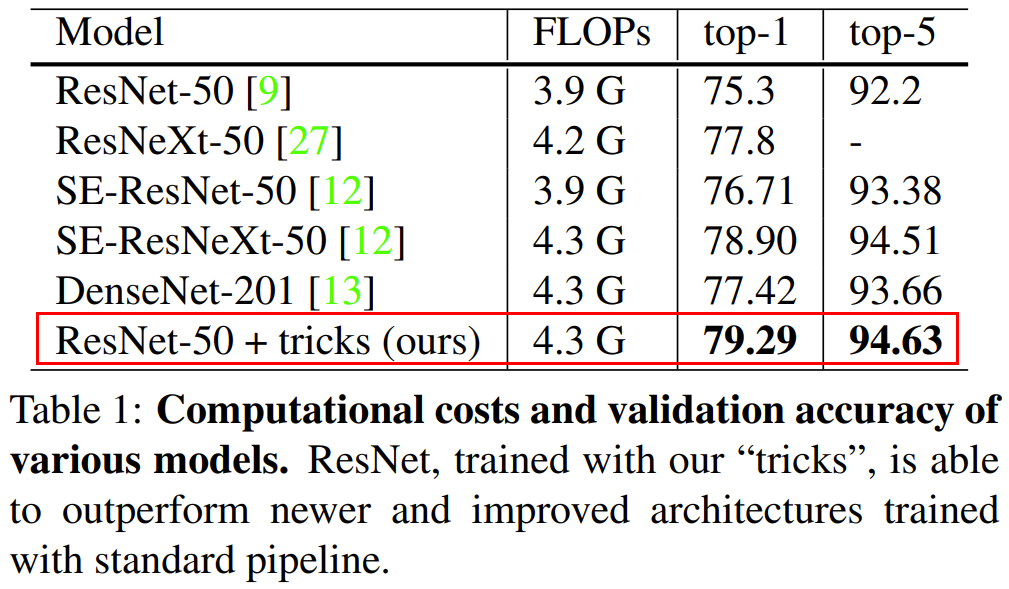
Image classification task에서 성능을 높이기 위해서는 더 좋은 더 큰 network 를 쓰면 되지만, network를 변경하는 것 이외에도 성능을 좌지우지하는 많은 요소들이 존재합니다.
본 논문에서는 ResNet50을 기준으로 network architecture는 크게 변경하지 않고 여러 Trick 들을 실험한 결과를 제공합니다. 결과적으로, 여러 trick들을 적용하면 적용 이전보다 ImageNet Top-1 accuracy가 4% 가량이나 증가한다는 것을 보여줍니다(위의 Table 1).
모든 실험은 기본적으로 아래의 이미지 전처리 사용합니다.
Preprocessing pipelines
- Randomly sample an image and decode it into 32-bit floating point raw pixel values in [0, 255].
- Randomly crop a rectangular region whose aspect ratio is randomly sampled in [3/4, 4/3] and area randomly sampled in [8%, 100%], then resize the cropped region into a 224-by-224 square image.
- Flip horizontally with 0.5 probability.
- Scale hue, saturation, and brightness with coefficients uniformly drawn from [0.6, 1.4].
- Add PCA noise with a coefficient sampled from a normal distribution N(0, 0.1).
- Normalize RGB channels by subtracting 123.68, 116.779, 103.939 and dividing by 58.393, 57.12, 57.375, respectively.
무작위 샘플 추출 → 32bit decode(0~255) → 가로/세로 비율 특정 범위로 random crop(직사각형) → 224x224 로 resize → 수평 flip(prob = 50%) → Hue, Saturation, Brightness augmentation → PCA 노이즈 추가 → normalize
Additional Setting
- convolution filter, FC layer 의 weight 는 Xavier Initialization
- Batch normalization : 감마=1, 베타=0
- Optimizer : NAG(Nesterov Accelerated Gradient)
- # of GPU = 8
- Batch Size = 256
- Total Epoch = 120
- Initial learning rate = 0.1
- Learning rate decay : 30epoch 마다 lr/=10 step decay
논문에서 적용한 방법들은 크게 3가지로, Efficient Training, Model Tweaks 그리고 Training Refinement 입니다. 아래에서 각각의 방법론에 대해 설명하려 합니다.
1. Efficient Training
이 파트에서는 딥러닝 네트워크에 효율적인 학습방법을 적용하여 학습 속도와 성능을 높이는 방법을 소개합니다. 크게 Large-batch Training 과 Low-precision Training 을 제시하고 있습니다. 일반적인 경우, batch size가 크면 수렴이 느려질 수 있는데 이를 해결하기 위한 다양한 연구가 진행되었습니다.
1.1 Linear Scaling Learning Rate
'Accurate, large minibatch SGD: training imagenet in 1 hour' 논문에 따르면 batch size를 키울수록 linear하게 learning rate를 키우는 것이 좋습니다. (보통 training 속도를 위해 메모리가 꽉 찰 때까지 batch size를 키우기 때문에 각자 실험환경에 따라 batch size와 learning rate 설정이 달라지기 때문에 위와 같은 연구도 진행되었었습니다.)
1.2 Learning Rate Warmup
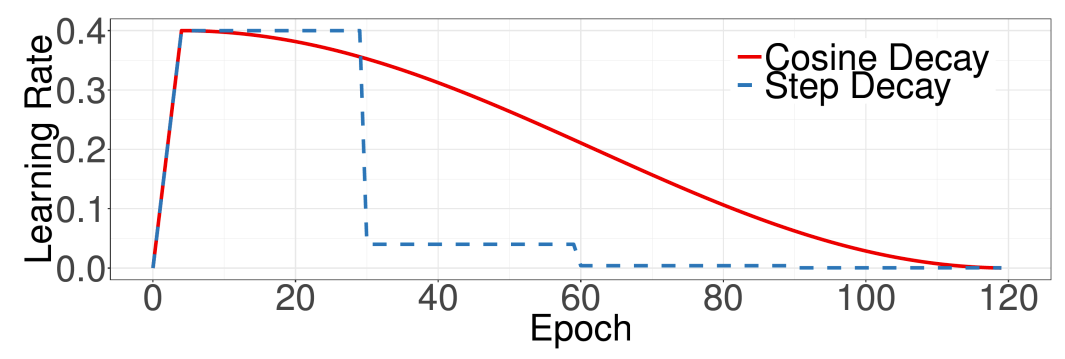
일반적으로 learning rate 는 initial setting 값에서 조금씩 줄여주는 방식으로 사용합니다(e.g. step decay, cosine decay,...etc). 하지만, learning rate warmup 방식은 초기 learning rate를 0으로 설정하고 일정 기간 동안 linear 하게 키우고(warmup) 그 뒤에 learning rate decay를 적용합니다. (이 방법도 위에서 언급한 논문에서 제안합니다.)
위 그림을 보면 초기에 5epoch까지 선형적으로 learning rate를 initial setting 값까지 키우고 그 뒤에 learning rate decay를 적용한 것을 볼 수 있습니다. 이러한 heuristic은 training에 도움을 줍니다.
1.3 Zero Gamma in Batchnorm
Batch normalization layer에서 input x와 곱하는 값인 gamma는 beta와 마찬가지로 trainable한 parameter이므로 학습 전 initialize를 해줘야합니다. 일반적으로 gamma=1, beta=0 으로 intialize 하는데, ResNet 같이 residual connection이 있는 network를 학습할 때는 gamma를 0으로 initialize 해주는 것이 학습 안정성을 높여준다고 합니다.
1.4 No Bais Decay
'Highly scalable deep learning training system with mixed-precision: Training imagenet in four minutes' 논문에 따르면 L2 regularization 에서 weight 에만 decay를 적용하는 것이 overfitting을 방지하는데 효과적이라고 언급합니다. 본 논문에서도 weight 이외에는 decay를 적용하지 않습니다. bias 뿐만 아니라, batch norm의 gamma, beta에도 적용하지 않스빈다.
1.5 Low-precision Training
일반적인 neural network에서는 32-bit floating point(FP32) precision을 이용하여 학습을 시키는데, 최신 하드웨어에서는 lower precision(FP16) 계산이 지원되면서 속도에서 이점을 얻을 수 있습니다. 하지만, FP16으로 precision을 줄이면 수를 표현하는 범위가 줄어들면서 학습 성능이 저하될 수 있습니다. 본 논문에서는 이를 해결하기 위해 Mixed precision training을 적용하여 network를 학습시킵니다.
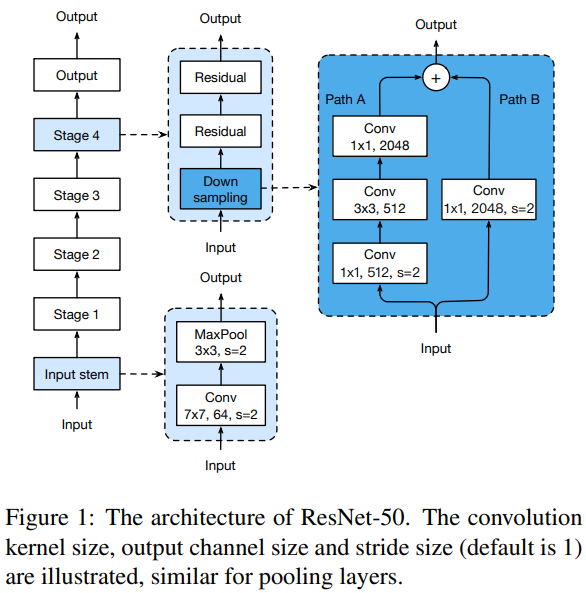
2. Model Tweaks
Model Tweaks에서는 ResNet architecture의 마이너한 수정을 통해 성능을 높이는 방법을 제안합니다. 좌측 그림은 vanilla ResNet 구조이고, 우측의 ResNet-B, ResNet-C, ResNet-D는 본 논문에서 제안하는 구조이며 resnet의 input stem 또는 down sampling 구조를 변경합니다.
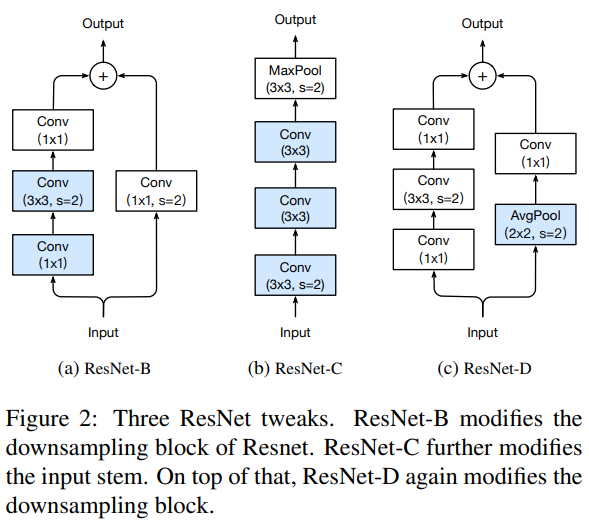
- ResNet-B
ResNet의 downsampling module을 일부 변경하는 구조입니다. Path A에서 convolution이 stride 2인 1x1을 사용하기 때문에 input feature map의 일부를 무시합니다.(1x1 인데 stride2이면 한칸씩 건너뛰면서 보니까) ResNet-B는 path A의 처음 두 convolution 의 stride를 변경하여 이를 보완합니다. 1x1은 stride 1로, 3x3 은 stride 2로 변경하는데 3x3은 stride 2더라도 filter가 겹치는 부분이 있기 때문에 무시되는 feature map 구간이 없어집니다.
- ResNet-C
이 방법은 inception-v2에서 처음 제안되었고, SENet, PSPNet, DeepLabV3, ShuffleNet 등에서도 사용합니다. convolution의 계산비용이 kernel width 또는 height에 quadratic입니다.(7x7 kernel은 3x3 kernel에 비해 5.4배입니다.) 따라서 이 tweak에서는 ResNet 제일 첫 convolution인 7x7 kernel의 convolution을 3개의 3x3 convolution 으로 대체합니다.
- ResNet-D
ResNet-B에서 영감을 받아 downsampling 블록의 path B에 있는 1x1 convolution 또한 input feature map의 일부를 무시합니다. feature 가 무시되지 않도록 변경하기 위해 stride가 1로 변경된 1x1 convolution 이전에 2x2 average pooling layer를 추가합니다. 이와 같은 방법이 경험적으로 잘 동작하고 computational cost에 거의 영향을 끼치지 않는다는 것을 발견합니다.
그냥 1x1 conv stride 2를 stride 1로 바꾸면 그 연산에서 만큼은 연산량이 2배가 되기때문에, average pooling 으로 feature spatial size를 줄이고 stride 1의 1x1 conv 를 사용하는 것입니다.
Experimental Results of Model tweaks
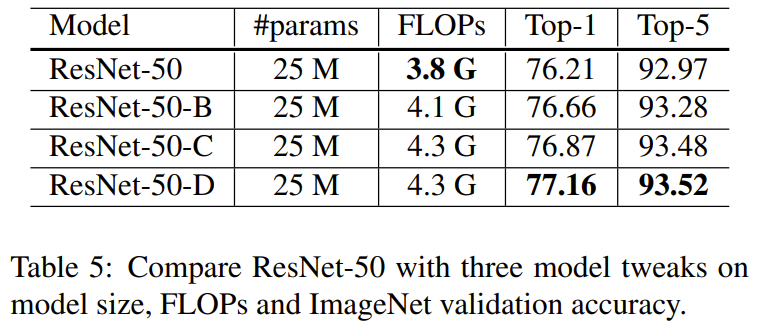
실험 결과는 ResNet-D가 약간의 FLOPS 증가가 있지만, Top-1 accuracy가 1% 가량 증가하는 것을 볼 수 있습니다.
3. Training Refinement
이 파트에서는 성능을 높이기 위해 아래 4가지 방법들을 제안합니다.
3.1 Cosine Learning Rate Decay
cosine 함수를 사용하여 learning rate를 변경하는 decay 방법이며, 이 방식으로 성능을 향상시킬 수 있다고 합니다.
3.2 Label Smoothing
기존에는 classification task에서 network를 학습시킬 때 정답은 1 나머지는 0인 one-hot vector를 label로 사용합니다.
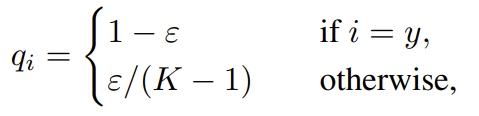
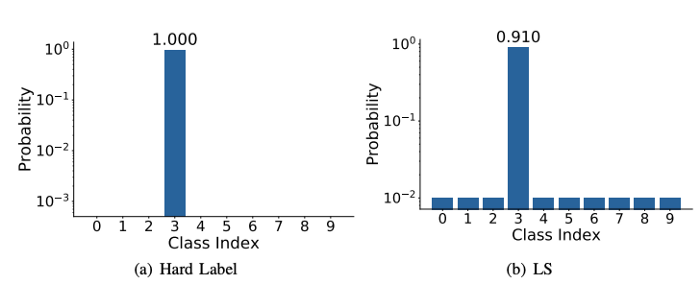
Label smoothing은 1,0 대신 smoothing 된 label을 사용합니다.
3.3 Knowledge Distillation
Knowledge distillation은 성능이 좋은(학습된) teacher model로 parameter 가 더 적고 연산량이 적은 student model을 학습시켜서 teacher model의 성능을 따라가도록 학습시키는 방법입니다.
Teacher model로 ResNet152 를 사용하고 student model은 Resnet50을 사용합니다.
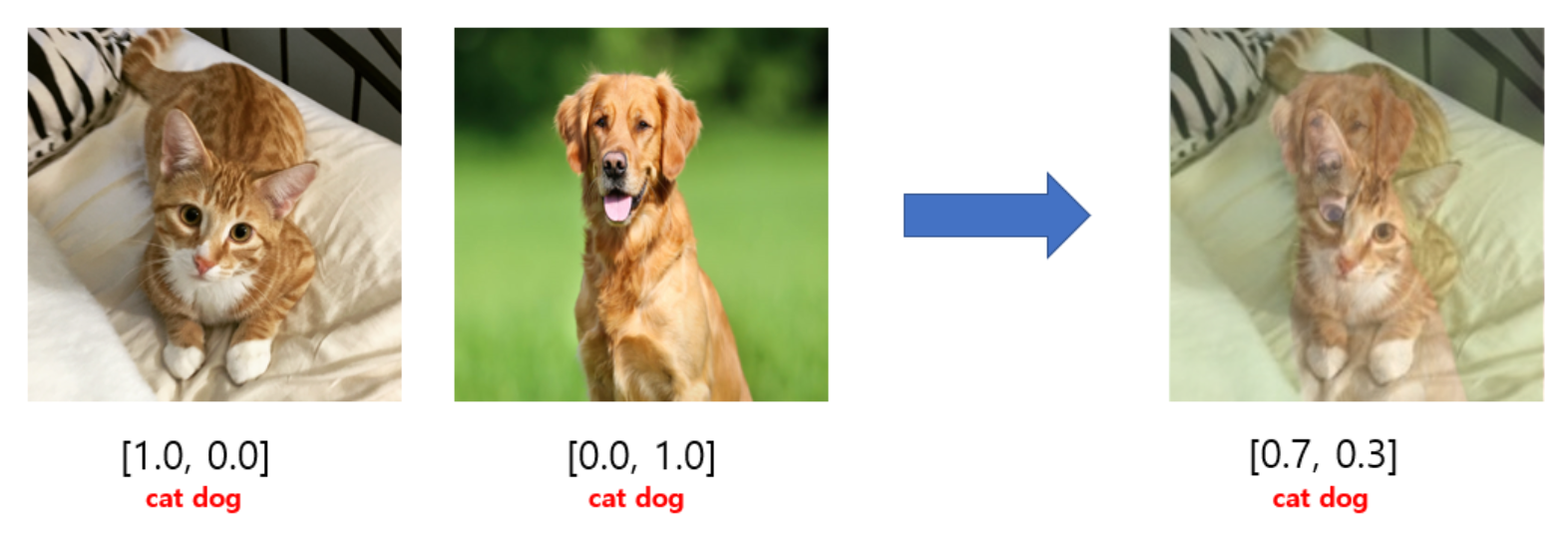
3.4 Mixup Training
Mixup augmentation은 image space에서 두 image와 label을 weighted linear interpolation하여 새로운 샘플을 생성하는 방법이며 weight 비율에 따라 정답 label의 비율도 달라집니다.
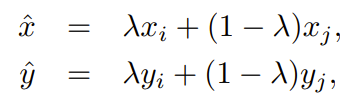
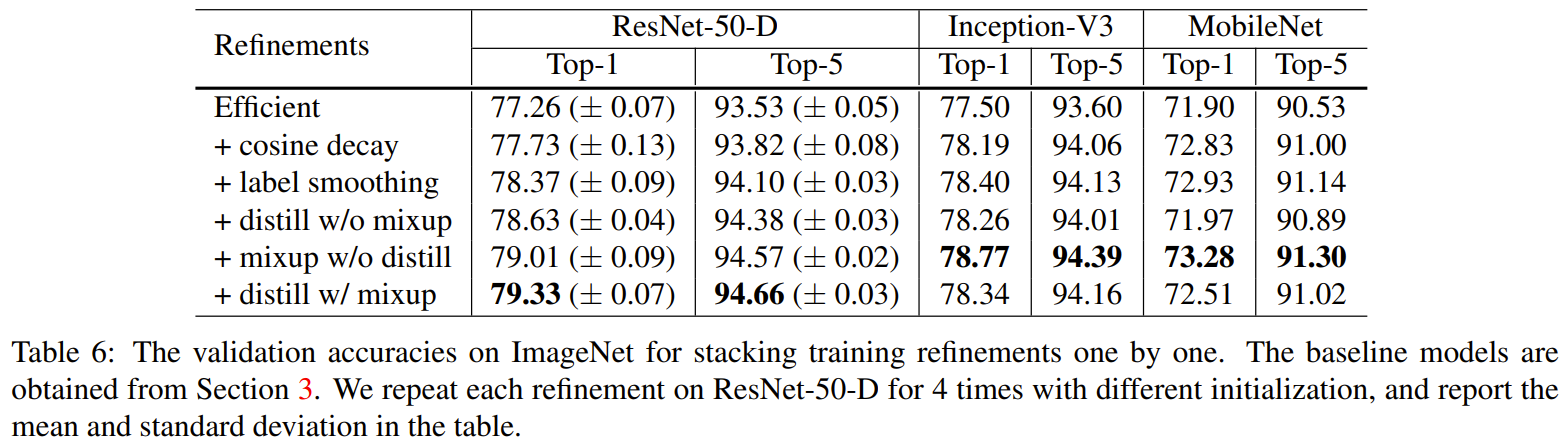
Experimental Results of Training Refinement
Transfer Learning - Object detection, Semantic segmentation
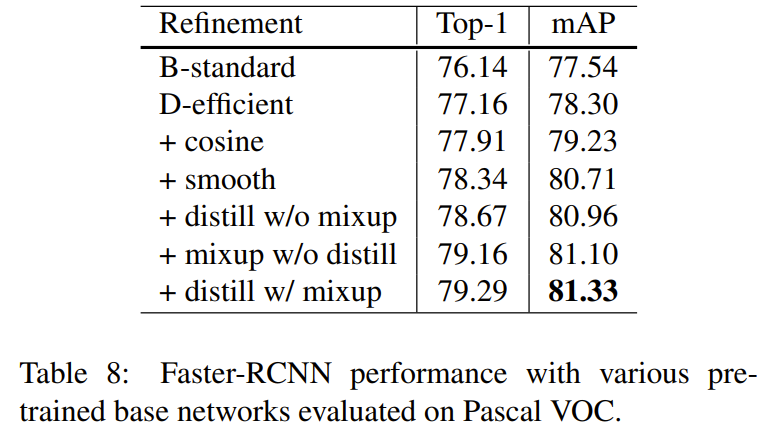
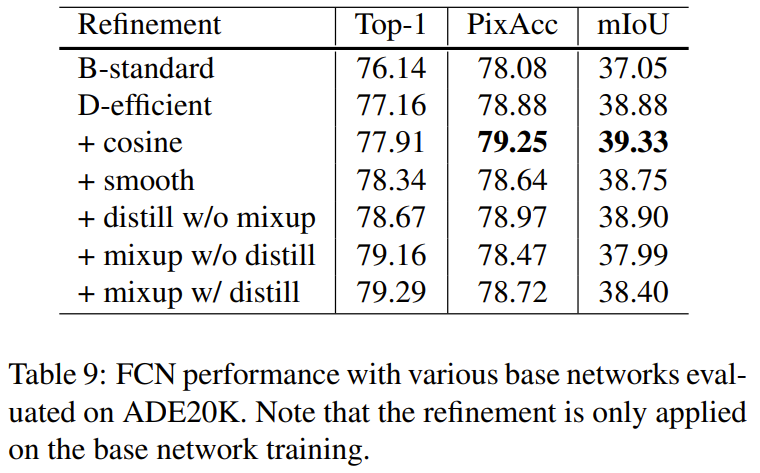
위에서 classification에 적용했던 여러 방법들을 object detection, semantic segmentation에 적용합니다. 실험결과는 대부분 성능이 향상되지만 segmentation task에서는 label smoothing 과 mixup 등은 오히려 안좋은 효과를 가져옵니다.
본 논문에서는 여러 많은 논문에서 소개되었던 deep neural network 의 training 기법들을 하나하나 실험한 결과를 제공합니다. 결론적으로 classification task에서 network를 develop 하는 것 이외의 여러 방법론들이 network의 성능 및 효율성을 높여준다는 것을 보여줍니다. 또한 classification 이 아닌 다른 task에도 적용되는 방법론들이 많으니, 딥러닝으로 모델을 training 시켜야하는 경우 꼭 참고하면 좋은 논문입니다.
'🏛 Research > Image Classification' 카테고리의 다른 글
| [튜토리얼] 이미지 분류 예제 코드 소개 | Image Classification | Pytorch (0) | 2023.08.11 |
|---|---|
| [간단 설명] 기본적인 CNN 아키텍처 설명 | VGGNet, ResNet, Densenet (0) | 2022.02.02 |
