💡 BLIP-2
1. 연구 주제와 주요 기여

BLIP-2 논문은 Multi-modal Vision Language Pre-training(VLP)에 대한 비용 효율적인 새로운 접근법을 제안했어요. 기존의 큰 모델을 end-to-end 로 학습시키는 방식의 높은 계산 비용을 해결하기 위해, 이미 학습된 이미지 인코더와 대형 언어 모델(LLM)을 고정(frozen)한 채로 사용하는 방법을 고안했어요.
- Querying Transformer(Q-Former): Modality Gap(이미지와 텍스트 간의 차이)를 효과적으로 줄이기 위한 경량 모듈을 제안했어요.
- Two-stage Pre-training: 기존 모델의 강점을 결합한 Representation Learning과 Generative Learning 전략으로 성능과 효율성을 모두 잡았어요.
- Flamingo 등과 비교해 54배 적은 Trainable Parameters로도 최고 성능을 달성했어요.
2. CLIP, BLIP, BLIP-2 비교
| 특징 | CLIP | BLIP | BLIP-2 |
| Pre-training 방식 | Image-Text Contrastive Learning |
Contrastive Learning + Generative Learning |
Two-stage Learning (Representation + Generative) |
| 모델 구조 | Dual-Encoder | Encoder-Decoder | Q-Former + Frozen Image/Language Models |
| Trainable Parameters |
약 428M | 약 583M | 약 188M |
| 주요 특징 | 텍스트와 이미지 간 Representation Alignment | Image Captioning 및 VQA 가능 | 효율성과 성능의 균형 |
| 장점 | 빠른 학습 속도 | 생성 기반 작업에 유리 | 최소한의 계산 비용으로 SOTA 성능 |
| 한계 | Generative 능력 부족 | 계산 비용이 크다 | Frozen Models 의존성 |
3. 연구 배경 및 동향
Vision-Language 연구는 이미지와 텍스트 간의 Representation 학습으로, Image Captioning, Visual Question Answering(VQA), Image-Text Retrieval 같은 작업에서 활발히 발전해왔어요.
기존 CLIP(Radford et al., 2021)는 효율적인 Contrastive Learning 방식을 통해 강력한 Zero-shot 성능을 보여줬지만, Generative Task에서는 한계가 있었고, BLIP(Li et al., 2022)는 Contrastive와 Generative Task를 모두 지원했지만, 계산 비용이 많이 드는 문제가 있었어요.
최근에는 Flamingo(Alayrac et al., 2022)처럼 Frozen Models를 활용하여 효율성을 높이는 방향으로 발전하고 있어요.
4. 주요 제안
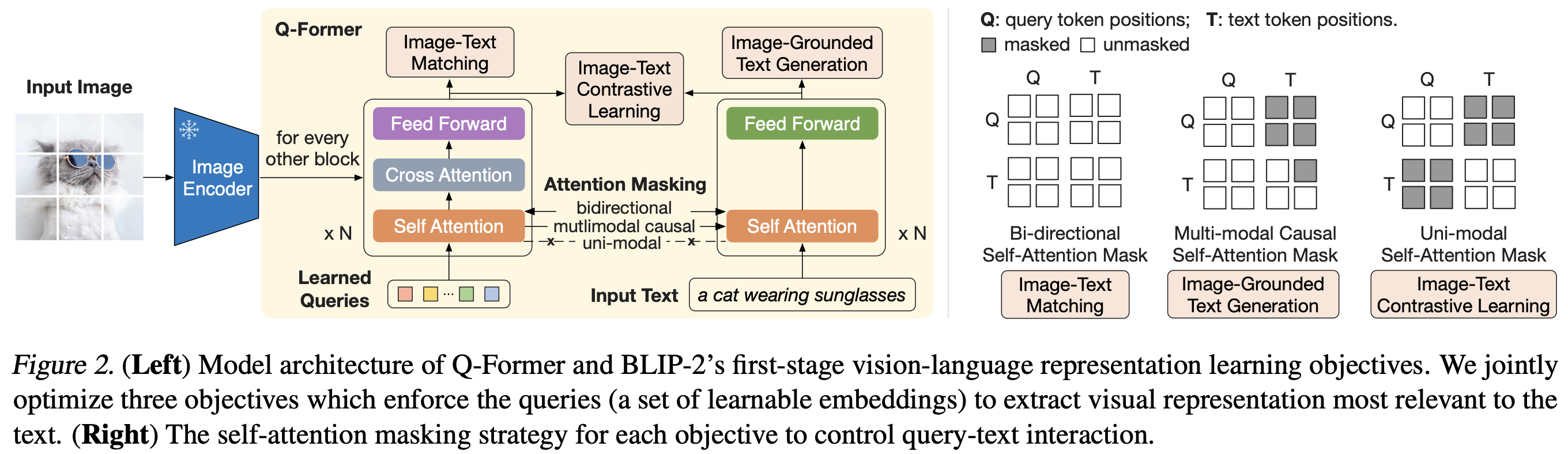
BLIP-2의 핵심은 Q-Former와 이를 기반으로 한 Two-stage Pre-training이에요. 이 구조는 Frozen Image Encoder와 Frozen LLM 간의 Modality Gap(모달리티 격차)을 효율적으로 해소하고, 계산 자원을 아끼면서도 높은 성능을 구현할 수 있도록 설계되었어요.
4.1. Q-Former
Q-Former는 Frozen Image Encoder와 Frozen LLM을 연결하는 경량 Transformer 모듈로, 두 모달리티 간의 정보를 효율적으로 교환하기 위해 설계되었어요. 이 모듈은 다음과 같은 주요 기능을 수행합니다.
4.1.1. Learnable Query Vectors
Q-Former는 Learnable Query Vectors라는 학습 가능한 벡터를 통해 이미지 인코더의 고정된 시각적 표현에서 가장 유용한 정보를 추출해요. 예를 들어, 이미지 인코더에서 257개의 이미지 특징 벡터를 출력했다면, Q-Former는 32개의 Query Vectors를 학습해 이 중 텍스트 생성에 필요한 핵심 정보만 요약해서 가져와요.
이 과정에서 Cross-Attention 메커니즘을 활용해 Query와 이미지 특징 간의 상호작용을 수행하며, 정보의 중요도를 판단해 필수적인 시각적 단서를 선택합니다. 이 방식은 텍스트 생성과 같은 언어 작업에 필요한 정보만 선별적으로 전달하기 때문에, 모델의 효율성과 성능을 동시에 확보할 수 있어요.
4.1.2. Bottleneck 역할
Q-Former는 이미지 인코더와 LLM 사이에서 정보 bottleneck 역할을 해요. 이미지 인코더가 출력하는 대규모의 시각 정보를 LLM이 효율적으로 처리할 수 있도록 필요한 핵심 정보로 간소화하는 데 중점을 둡니다. 이 과정에서 Learnable Query Vectors를 활용해 필수적인 시각적 단서를 추출하고, 이를 LLM에 전달하여 텍스트 생성이나 질문 응답과 같은 작업을 수행할 때 필요한 최소한의 정보를 포함하도록 설계돼요. 이렇게 정보의 양을 줄이면서도 중요한 내용을 놓치지 않도록 최적화함으로써 모델의 계산 자원을 절약하고 성능을 유지할 수 있어요.
4.1.3. Transformer의 두 가지 모드
Q-Former는 이미지와 텍스트 간의 정보를 효과적으로 처리하기 위해 내부적으로 두 가지 모드의 Transformer를 포함하고 있어요.
- Image Transformer: Learnable Query Vectors가 Frozen Image Encoder의 출력과 상호작용하여 이미지 데이터를 처리합니다. 이 과정에서 이미지의 고정된 특징 표현에서 텍스트 생성에 필요한 시각적 정보를 선택적으로 추출해요.
- Text Transformer: Query Vectors가 Frozen LLM과 상호작용하며, 텍스트 생성이나 질문 응답에 필요한 정보를 전달합니다. 이 과정에서 선택된 시각 정보는 자연어로 변환되는 데 사용돼요.
이 두 가지 모드는 각각 시각 정보의 이해와 언어적 표현 간의 다리 역할을 하며, 두 모달리티의 격차를 줄이고 정보를 효율적으로 교환할 수 있도록 돕습니다. 이러한 설계는 BLIP-2가 다양한 Vision-Language 작업에서 뛰어난 성능을 발휘하는 데 핵심적인 역할을 해요.
4.2. Two-stage Pre-training
BLIP-2는 Q-Former를 학습시키고 Vision-to-Language 작업을 최적화하기 위해 Representation Learning과 Generative Learning의 두 단계 Pre-training 전략을 사용해요. 이러한 전략은 계산 자원을 효율적으로 사용하면서도 높은 성능을 구현하도록 설계되었답니다.
4.2.1. Representation Learning
Representation Learning은 이미지와 텍스트 간 강력한 멀티모달 표현을 학습하는 첫 번째 단계예요. 이 단계는 이미지와 텍스트 사이의 관계를 정렬하고, 필요한 정보를 정확히 추출할 수 있도록 Q-Former를 학습하는 데 중점을 둡니다. 주요 학습 목표는 다음과 같아요.
1) Image-Text Contrastive Learning (ITC)
ITC는 이미지와 텍스트를 벡터 공간에서 정렬(align)하는 작업이에요. Q-Former의 Query Vectors는 이미지의 시각적 특징을 추출한 뒤, 이를 텍스트 표현과 비교해 positive pairs를 가까이, negative pairs를 멀리 위치하도록 학습해요.
예를 들어, "고양이가 선글라스를 쓰고 있는 이미지"와 "고양이가 선글라스를 쓰고 있다"는 텍스트는 positive pair로 간주돼요. 반면, "강아지가 뛰어놀고 있는 이미지"는 negative pair로 처리됩니다.
이 작업을 통해 이미지와 텍스트 간 전반적인 의미적 일치를 학습해요.
2) Image-Text Matching (ITM)
ITM은 이미지와 텍스트 간의 Fine-grained Alignment를 학습해요. 모델은 주어진 이미지와 텍스트 쌍이 일치하는지 여부를 이진 분류 방식으로 학습하고, 텍스트와 이미지 간의 세밀한 관계를 이해하도록 돕습니다.
예를 들어, "사과"라는 텍스트와 "사과 사진"은 positive pair로 학습되지만, "바나나"라는 텍스트와 "사과 사진"은 negative pair로 학습돼요.
이 과정은 모델이 텍스트와 이미지 간의 구체적이고 세밀한 맥락을 이해하도록 만듭니다.
3) Image-grounded Text Generation (ITG)
ITG는 텍스트 생성에 필요한 시각적 정보를 추출하도록 Q-Former를 학습하는 과정이에요. Query Vectors는 이미지에서 텍스트 생성에 필수적인 정보를 선별적으로 추출하고, 이를 텍스트 Transformer에 전달해 자연스러운 텍스트를 생성하도록 학습해요.
예를 들어, 사진 설명 생성 작업에서 "이 사진은 선글라스를 쓴 고양이를 보여줍니다"와 같은 텍스트를 생성하도록 학습합니다.
Representation Learning의 의미
Representation Learning은 LLM이 처리해야 할 시각 정보의 양을 줄이고, Q-Former가 최적화된 시각 표현을 LLM에 전달할 수 있도록 학습하는 기초 단계예요. 이를 통해 Frozen Image Encoder와 Q-Former 간 협력을 강화하고, 텍스트 생성에 필요한 시각적 정보를 효율적으로 정렬합니다.
4.2.2. Generative Learning: 텍스트 생성 최적화

Generative Learning은 Representation Learning 이후 진행되는 두 번째 단계로, LLM과의 연결을 최적화해 텍스트 생성 능력을 강화하는 데 초점을 맞추고 있어요. 이 단계는 LLM이 시각 정보를 자연어로 변환하는 과정을 정교하게 조율합니다.
1) Soft Prompting with Q-Former
Q-Former는 Frozen LLM과 직접 연결되지 않고, Query Representation을 Soft Prompt로 변환해 LLM의 입력으로 제공해요. 이 방식은 LLM의 구조나 가중치를 변경하지 않으면서도, 시각적 정보를 텍스트로 표현하는 능력을 자연스럽게 강화해줍니다.
예를 들어, 이미지에서 추출한 Query Representation을 "이미지 설명:"이라는 텍스트와 결합해 입력하면, LLM이 "고양이가 선글라스를 쓰고 있다"와 같은 문장을 생성하도록 유도해요.
2) Decoder-based LLM (OPT)와 Encoder-Decoder LLM (FlanT5)의 차이
- OPT (Decoder-only)
Query Representation은 LLM의 입력 텍스트에 앞에 붙는 추가 토큰처럼 동작해요.
(예시: "이미지 설명: 고양이가 선글라스를 쓰고 있다.") - FlanT5 (Encoder-Decoder)
Query Representation은 LLM의 인코더 입력과 결합돼 텍스트 생성 과정을 돕습니다.
(예시: "이미지 설명 생성 -> 텍스트 출력.")
Generative Learning의 의미
Generative Learning은 Q-Former가 추출한 시각 정보를 Frozen LLM에 효과적으로 전달하고, 이를 기반으로 자연스러운 텍스트를 생성하는 능력을 최적화하는 단계예요. 이 접근법은 LLM의 구조를 변경하지 않으면서도 강력한 Vision-to-Language 성능을 구현할 수 있도록 돕습니다.
4.2.3. Two-Stage Pre-training의 강점
Representation Learning과 Generative Learning의 조합은 BLIP-2가 적은 Trainable Parameters로도 높은 성능을 달성할 수 있도록 해줍니다.
- Frozen Models을 활용해 최신 모델의 강점을 최대한 활용하면서 계산 자원을 절약해요.
- Q-Former는 Vision-to-Language 작업에서 필수적인 정보만 선별적으로 전달해 효율성을 극대화해요.
- 이러한 접근은 시각적 데이터를 효과적으로 언어적 표현으로 변환하는 데 최적화되어, 다양한 Vision-Language 작업에서 뛰어난 성능을 발휘합니다.
BLIP-2의 Two-Stage Pre-training 전략은 Vision-Language 연구의 새로운 기준을 제시하며, 효율성과 성능의 완벽한 균형을 보여줍니다.
5. 실험 결과


BLIP-2는 다양한 Vision-Language 작업에서 뛰어난 성능을 입증하며, 효율성과 정확성을 동시에 보여줬어요. Zero-shot VQA 작업에서 Flamingo80B 대비 8.7% 더 높은 정확도(65.0%)를 기록했으며, 이는 54배 적은 Trainable Parameters로 달성된 결과로 모델의 경량화와 효율성을 잘 보여줍니다. 이미지 설명 생성에서는 COCO와 NoCaps 데이터셋에서 각각 CIDEr 점수 145.8과 121.6으로 최고 성능을 기록하며, 이미지의 시각적 정보를 자연스러운 텍스트로 변환하는 능력을 입증했어요. 또한, 이미지-텍스트 검색에서는 Flickr30K와 COCO 데이터셋에서 Recall@1 기준 각각 97.6%와 85.4%를 달성하며, 텍스트와 이미지 간의 관계를 정교하게 이해하는 모델의 강점을 보여줬습니다. 이러한 결과는 BLIP-2가 적은 자원으로도 높은 성능을 구현하며, 다양한 Vision-Language 작업에서 다목적성과 일반화 능력을 갖춘 모델임을 나타냅니다.
6. 결론
BLIP-2는 멀티모달 AI에서 계산 효율성과 성능을 혁신적으로 결합한 모델로, Q-Former를 활용해 고정된 이미지 및 언어 모델 간의 간극을 효과적으로 해소하며 새로운 가능성을 열어줬어요. 고정된 언어 모델(OPT, FlanT5 등)에 의존하는 만큼 선택한 언어 모델의 품질이 성능에 영향을 미치고, 다중 이미지-텍스트 시퀀스 데이터 세트 부족으로 인해 in-context learning 성능이 제한적이라는 한계도 있지만, 이러한 문제는 더 풍부한 데이터와 모듈 개선을 통해 충분히 보완 가능성이 있습니다.
BLIP-2는 CLIP과 BLIP의 강점을 모두 이어받으면서도 효율성을 극대화한 점이 돋보이며, 실용성과 확장성 측면에서 멀티모달 AI의 새로운 기준을 제시했어요.