
Open AI에서 게재한(ICML2021) Contrastive Language-Image Pre-training(CLIP)를 제안한 논문을 소개합니다.
Introduction & Motivation
딥러닝이 computer vision의 거의 모든 분야에서 굉장히 잘 활용되지만 현재 접근 방식에는 몇가지 문제가 있습니다. 기존의 vision model들은 학습된 task에는 성능이 우수하지만 새로운 task에 적용시키기 위해서는 새로 학습을 시키야 하는(그러면 새로운 데이터셋과 추가 레이블링이 필요..) 번거로움(?) 이 있습니다. 벤치마크에서 잘 수행되는 몇몇 model들은 stress test에서 좋지 않은 결과를 보여주기도 합니다.
대안으로 raw text와 image를 pair로 학습시키는 방법이 있습니다. 본 논문에서는 인터넷에서 풍부하게 사용할 수 있는 다양한 natural language supervision을 통해 다양한 이미지에서 학습되는 network를 제안합니다.
간단하게 얘기하면, 기존의 image classification model은 사용하는 dataset이 고정된 label을 갖습니다. 때문에 image만 feature space 로 embedding하여 prediction하고, 정답 label과 비교하여 loss를 계산하여 학습합니다. 하지만, 제안하는 방법은 웹상에서 image-text 쌍으로 가져오기 때문에 고정된 label이 아니고 심지어 text는 문장의 형태를 포함합니다. 때문에 text와 image를 모두 feature space로 embedding하고 이들의 similarity를 계산하여 학습하는 방법을 사용합니다.
Pre-training 후에 자연어는 visual concept를 참고하는데만 사용되어 downstream tsak로 zero-shot transfer 를 가능하게 합니다. model은 많은 task에 transfer가 성공적이고 심지어 기존의 supervision model 보다 좋은 성능을 보여주기도 하지만, 여전히 complex한 task에는 적용하기 힘든 한계점을 보여주기도 합니다.
NLP 분야는 잘 모르지만...(Attention Is All You Need 정도?..) 본 논문에 따르면 웹에서 가져온 raw text로 pre-training한 모델이 기존의 supervision model(사람이 레이블링한 데이터셋으로 학습한) 의 성능을 능가한다고 합니다. 하지만, 이때까지 vision 분야에서는 raw text 로 pre-training하는 방법은 없었고 본 논문에서 시도하여 좋은 성과를 이끌어 냅니다.
image-text pair의 multi-modal 에 대한 연구는 오랫동안 지속되어 왔지만, 자연어를 이미지 representation learning에 활용하는 것은 여전히 드물다고 합니다. 이유는 성능이 그만큼 잘 안나왔다고 합니다. 대신 2018년 논문에서는 weakly supervised learning으로 인스타그램 이미지에서 ImageNet과 관련된 해쉬태그를 예측하는 것이 효과적인 pre-training 방법임을 보여주긴 했습니다.
본 논문에서는 위에서 언급한 weakly supervised approach와 zero shot learning using raw text approcah 간의 간극을 줄이기 위해 Contrastive Language-Image Pre-training(CLIP) 라는 방법을 제안합니다.
* Natural Language Supervision 을 사용하는 이유?
자연어 관련 지식이 부족하여 왜 자연어로 supervision learning을 하는지에 대한 논문에 언급된 내용을 정리합니다.
1) 기존에 vision task에서 사용되던 label에 비해 scaling이 쉽습니다.
기존에 사람이 직접 레이블링을 했지만, 그런 과정이 필요없고 자연어를 이용한 학습은 인터넷의 방대한 자료에 포함된 텍스트를 supervision으로 사용하여 학습이 가능합니다.
2) 언어에 대한 representation을 학습한다는 장점이 있습니다.
자연어를 이용하는 학습 방법은 un/semi/self-supervised learning 방법과는 달리 이미지 representation 뿐만 아니라, 언어 representation을 가지기 때문에 조금 더 유연하고 robust한 장점을 가지게 됩니다.
CLIP

1. Contrasive pre-training
인터넷에 공개된 많은 데이터셋을 통해 4억개의 이미지-텍스트 쌍으로 새로운 데이터셋을 구축하여 CLIP를 pre-training합니다. N개의 이미지-텍스트 pair가 주어졌을 때, CLIP는 image embedding feautre와 text embedding feature들로 NxN개의 cosine similarity map을 만듭니다. 그리고 positive pair(정답)의 similarity는 최대화하고 나머지 N^2-N 개의 negative pair(오답)의 similarity는 최소화하는 방향으로 image encoder와 texte encoder를 학습하여 multi-modal embedding space를 학습합니다.
또한 제안하는 method에서는 정확한 단어가 아닌 텍스트 전체로 짝지어져 학습을 시켰습니다.
Image encoder로는 ResNet50과 Vision Transformer(ViT)를 사용하고 Text encoder로는 Transformer를 사용했습니다.
2. Create dataset classifier from label text / Use for zero-shot prediction
CLIP는 이미지의 정확한 단어를 예측하도록 학습하지 않고 텍스트 전체로 짝을 지어 학습시킵니다. 때문에 테스트 시에도 A photo of {object} 또는 A photo of {object}, a type of food 등의 텍스트에 모든 class label을 넣고 text encoder에 넣어 text imbedding feature를 만들고, image는 image encoder를 통과시켜 image imbedding feature 1개를 만듭니다. 이 때 모든 text feature들과 1개의 image feature 간의 similarity를 보고 가장 높은 similarity를 가지는 텍스트를 선택합니다.
아래와 같은 문장형식으로 prediction을 하는 이유는, 애완 동물의 종류 중 하나, 음식 중 하나, 등등의 추가 정보를 text encoding에서 반영할 수 있기 때문에 분류 성능이 향상되기 때문입니다.
- "A photo of a {label}, a type of pet."
- "a satellite photo of a {label}."
- "A photo of big {label}"
- "A photo of small {label}"
Experiments
본 논문에서 말하는 zero-shot 은 한번도 보지 못한 datasets에 대해 분류를 하는 작업을 말합니다. 저자들은 zero-shot transfer 를 task-learning capabilties를 측정하는 방법으로 생각합니다.
CLIP는 다양한 dataset과 task에서 fully supervision learning 방법과 비교하여 아래와 같이 경쟁력 있는 성능을 보여줍니다. 그 외에도 few-shot learning 과의 비교, vision sota와의 비교 등등에 대한 다양한 실험이 논문에 포함되어 있습니다.
* task : fine-grained object classification, geo-localization, action recognition and OCR,... etc
Zero-shot transfer 성능이 물체를 인식하는 task에서는 매우 우수하지만, 물체의 개수를 세거나 물체가 얼마나 가까이 있는지를 예측하는 조금 더 복잡한 task에서는 좋지 않습니다. 또한 fine-grained recognition 분야와 같은 이미지의 세밀한 차이로 클래스가 나뉘는 task에서도 성능이 좋지 않습니다.
* 논문에는 나와있지 않지만, 아마 웹에서 얻어진 이미지-텍스트 쌍에서 텍스트가 얼마나 이미지를 구체적으로 나타내는지가 중요할 것 같습니다. 하지만 대부분의 텍스트가 이미지를 러프하게 묘사할 것이므로 현재 방법은 웹에서 흔히 볼 수 있는 물체를 인식하는 task에서는 탁월한 transfer 성능을 가지지만, 특정 분야에 한정된 객체를 다루거나 매우 세밀한 차이가 중요한 task에서는 성능이 좋을 수 없을 것입니다.
여담인데, main 실험은 2주동안 256개의 V100 GPU로 진행합니다. 고로... 일반적인 대부분의 환경에서는 실험이 불가능합니다. GPU 가격만 1개당 600잡고 15억원 가량합니다...
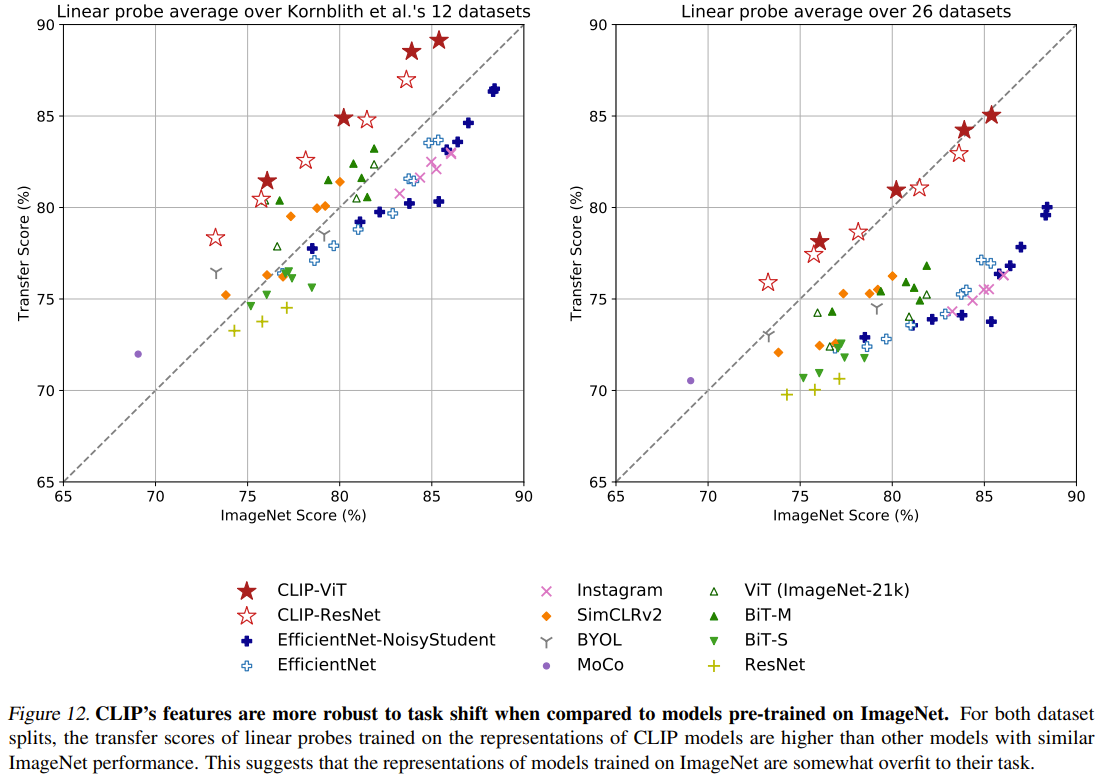

위 2개의 실험은 데이터의 distribution shift에 얼마나 robust한지 실험한 결과입니다. 첫 번째 실험(Fig 12)은 다른 task로 transfer 했을 때의 결과가 다른 method 들에 비해 CLIP가 월등히 좋은 것으로 보아 task shift에 robust하다고 볼 수 있습니다. 두 번째 실험(Fig 13)은 ImageNet으로 pre-training한 ResNet101과 CLIP의 distriution shift 에 대한 실험이고 결과는 역시 CLIP가 월등히 좋습니다.
이와 같은 결과는.... CLIP가 웹상에서 가져온 4억개의 데이터로 학습을 시키니까 학습 데이터의 distribution이 크고 많은 case의 이미지(실제 이미지, 그림, 스케치 등등)들을 포함하기 때문에 distribution shift에 robust할 수 있습니다.
* 딥러닝 모델의 경우 굉장히 성능이 좋은 것처럼 보일 수 있지만 실제로는 학습한 데이터에 굉장히 의존적인 결과를 가져오기도 합니다. Test set의 결과가 좋다하더라도 train data과 test data의 distribution이 거의 유사한 경우가 많기 때문에 distribution shift에 robust하다고 볼 수는 없습니다. 이러한 문제를 해결하기 위한 관련 task로 domain adaptation/generalization 이 있습니다.
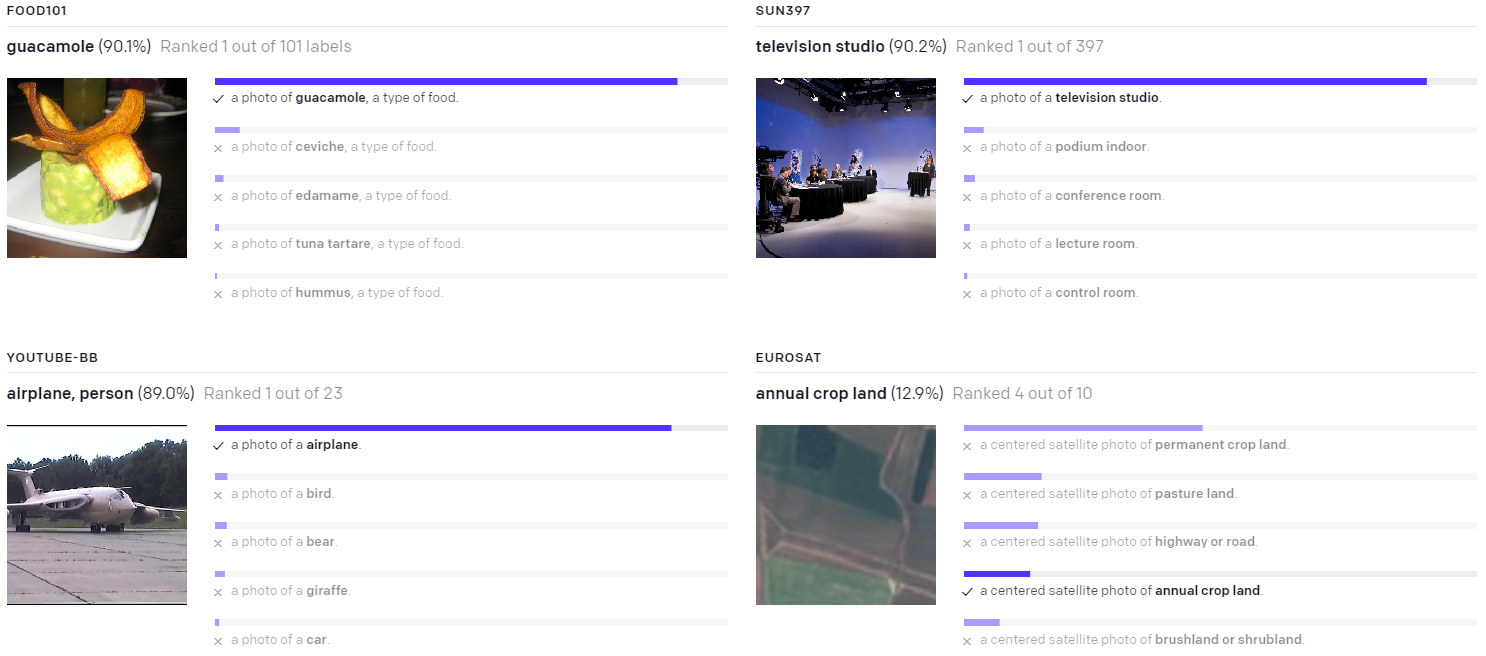
실제 결과
결론
CLIP는 이미지-자연어 쌍으로 task agnostic한 pre-training하여 다른 task의 딥러닝 성능을 향상시켜줄 수 있는 방법입니다. 자연어를 vision task에 성공적으로 활용한 방법이며 아주 많은 데이터와 강력한 computing power로 모델을 학습시켜 올인원 모델을 만든 느낌입니다. 하지만, 이들이 모든 task를 커버할 수있는 모델은 아니기 때문에 transfer/knowledge distillation 등을 사용하여 특정한 task의 model을 fine-tuning하여 비교적 쉽게 성능을 향상시킬 수 있을 것 같습니다.