CVPR 2020에 게재된 texture recognition 분야 논문입니다. Texture의 고유한 구조적인 특징을 분석하고 이를 활용하는 네트워크를 제안하여 texture recognition SOTA를 달성하고 ablation, main 실험 이외에도 fine-grained recognition, semantic segmenation 과 같은 응용 실험까지 포함된 논문입니다.
Abstract
Texture recognition은 다양한 primitive와 arrangement 가 동일한 texture 이미지에서 인식될 수 있기 때문에 어려운 task 입니다. CNN을 기반으로 한 최근 작업 중 일부는 spatial arrangement에 invariant 하도록 orderless aggregating을 활용합니다. 그러나 이는 real world 에서 texture 이미지를 구별하고 설명하는 중요한 단서인 texture의 structural property 를 무시합니다. 이 문제를 해결하기 위해 캡처된 primitive 간의 spatial dependency를 texture 인식을 위한 structural representation으로 활용하는 DSR-Net(Deep Structure-Revealed Network)를 제안합니다. Primitive Capture Module(PCM)은 8개의 directinal spatial context에서 multiple primitive를 생성하도록 고안되었고, 여기서 deep feature는 direction map의 constrain 하에서 추출된 다음 neighborhood 의 similarity를 기반으로 인코딩됩니다. 이러한 primitive는 Dependence Learning Module(DLM)과 연결되어 structural representation을 생성합니다. 여기에서 two-way collaborative relationship 전략이 도입되어 여러 primitive 간의 spatial dependency를 인식합니다. 마지막으로 structure-revealed texture representation과 spatial ordered information이 결합되어 texture를 인식합니다.
Introduction
Texture는 basic primitive set(textons)의 spatial organization을 말하며, 따라서 textrured region은 일반적으로 일부 statisticl properties를 따르며 주기적으로 반복되는 textons을 나타냅니다. 기존의 texture recognition 방법은 spatial arrangement의 invariance를 제공하는 데 탁월하지만, 일반적으로 texture primitive의 inherent structure를 캡처하는데 제한이 있습니다.
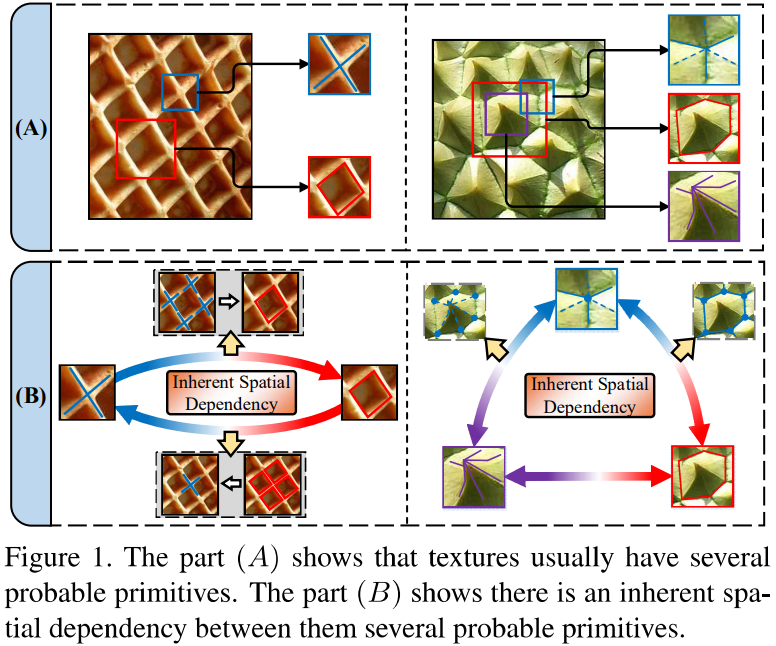
본 논문에서 제안하는 방법은 다양한 texture primitive가 서로 다른 spatial context(e.g. 주로 방향)로 인식될 수 있지만, 이러한 primitive 간의 spatial dependency가 존재한다는 관찰을 기반으로 합니다. 이 spatial dependency 는 spatial layout에 invariant 하며 texture의 inherent한 structural property를 나타냅니다. 예를 들어, 아래 그림(A)에서 동일한 texture 이미지에서 여러 primitive가 관측되고 이는 texture 인식을 어렵게 합니다. 그러나 이러한 primitive 사이에 고유한 structural dependency가 있다는 것을 발견할 수 있고 이는 spatial transformation과 brightness change에 invariant합니다. 이는 이러한 dependency가 primitive appearance 와 spatial organization의 가변성에 robust하고 texture 이미지의 구조적 표현으로 작용할 수 있음을 의미합니다.
아래 그림 와플에서 파란색 십자가 모양과 빨간색 사각형 모양이 서로 다른 primitive 이고, 이들이 texture 인식에 간섭을 줄 수 있으나, 이들 사이에 spatial dependency가 있으니 활용할 수 있다는 뜻입니다. 십자가 무늬가 반복되면 결국 사각형 모양이 생길 수 밖에 없으니 dependent한 특징이라는 뜻이고, 오른쪽 그림에서도 뾰족한 부분이 있으면 들어가 있는 부분도 생길 수 밖에 없으니 역시 spatial dependent한 특징입니다.

DSR-Net은 Primitive Capture Module(PCM)과 Dependence Learning Module(DLM)의 두 가지 모듈로 구성됩니다.
PCM은 8개의 direction map의 guidance와 constraint에 따라 deep feature를 생성하고, candidate primitive에 대한 robust representation을 캡처하기 위해 neighborhood의 similarity를 기반으로 인코딩합니다.
DLM은 two-way collarborative relationship strategy를 통해 이들 사이의 spatial dependency를 인식합니다.
Deep Structure-Revealed Network
DSR-Net 의 전체적인 architecture 는 위와 같고, Structur Revealed Branch와 Spatial Ordered Branch 두 개의 branch로 나뉩니다. ResNet50을 feature extractor로 사용하고 local spatial feature를 캡처하기 위해 서로 다른 level의 feature들을 추출합니다. 그런 다음, 서로 feature map들을 bilinear interporlation으로 upsampling하여 동일한 resolution으로 만들어 준 후 concat합니다. computation cost를 줄이기 위해 1x1 conv로 채널 수를 2048개로 줄입니다.
Wild의 texture 이미지는 하나의 균질한 표면으로 채워지는 경우가 거의 없고 orderless한 component와 order한 component를 모두 포함합니다. 이 문제를 해결하기 위해 orderless representation과 ordered information의 밸런스를 맞춰야하고 이를 위해 GAP를 적용합니다. 마지막으로, structure-revealed feature와 spatial ordered feature가 element-sum operation으로 병합됩니다.
- Primitive Capturing Module(PCM)
Texture 이미지 요소인 primitive는 다른 spatial context의 guidance에 따라 local로 캡처해야합니다. 따라서 제공된 spatial context constraint 조건으로 candidate primitive를 생성하기 위해 새로운 primitive capture 모듈이 고안되었습니다. 구체적으로 8개 방향의 context를 고려합니다. convolution kernel과 동일한 사이즈의 direction map이 convolution 과정에서 local context guidance로 제공됩니다. 그러나 direction map과 feature space 사이에는 갭이 있고, 방향 정보를 원래의 feature space에 매핑하기 위해 small convolution network이 고안되었고 다음과 같이 표현할 수 있습니다.
- cat : concatenation
- x : input feature
- D : direction map
- p = (w,h)
- x_p : kernel 과 동일한 사이즈의 feature
- f_D : embedding function
illumination 변화와 spatial distortion에 대해 robust 하도록 local relation networks for image recognition(ICCV2019) 에서 언급된 composition operation이 사용되고 이는 다음과 같이 표현됩니다.
- p_center : p의 center
- sigmoid : normalization operation 으로 사용
- 파이 : p와 p_center 간의 composability 측정 ( = -(p-p_center)^2)
- f_p, f_pcenter : transformation function
결국 feature 의 center 값과 feature의 각 위치 값들의 차이를 표현하는 것입니다.
primitive capture 프로세스는 다음과 같이 표현할 수 있습니다.
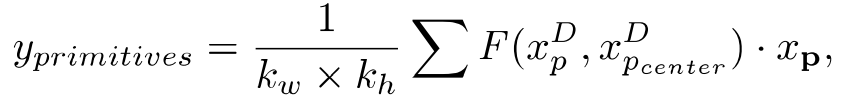
- Dependence Learning Module(DLM)

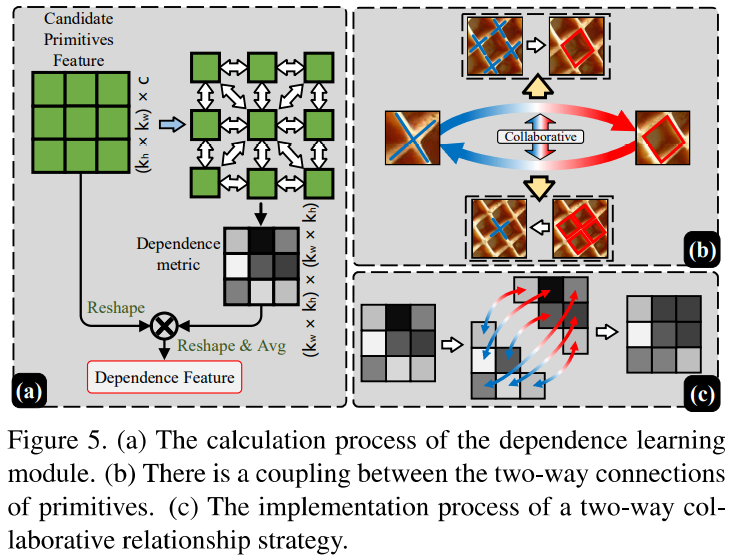
DLM은 local 범위에서 여러 candidate primitive 간의 dependency relationship을 설정하는 데 사용됩니다. local region의 feature x_p를 feature vector V의 set으로 간주합니다. 먼저 transformation에 입력하여 두 개의 새로운 feature V1, V2를 생성합니다. 그런 다음, V2와 V1의 transpose를 행렬곱하여 softmax layer를 적용하여 dependence matirex R을 계산합니다. (self-similarity map R을 생성)

여기서 r_ij는 j번째 위치에 대한 i번째 위치의 영향을 뜻합니다. 두 element의 feature가 유사할 수록 correlation이 커집니다.(=feature similarity) 현재 접근 방식은 두 element 간의 양방향 relationship을 설정하는 것입니다.
Figure 5 (b) 와 같은 two-way relationship의 correlation을 캡처하기 위해 Figure 5 (c)와 같은 collaborative strategy를 제안하여 dependence modeling 능력을 향상시킵니다.
Two-way collaborative strategy는 다음과 같이 표현할 수 있습니다.
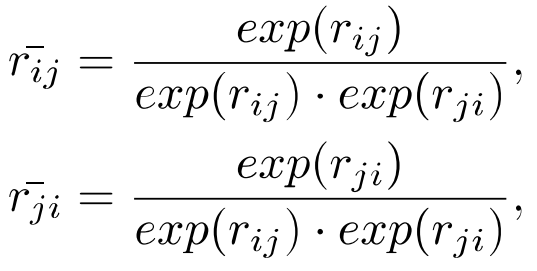
r_ij와 r_ji는 two-way collaborative operation 전에 처리되는 R의 two-way relationship입니다. 한편 새로운 feature V3를 생성하기 위해 feature V를 convolution layer에 넣습니다. 그런 다음, V3와 R의 transpose를 행렬곱합니다. 마지막으로, feature V를 element-wise sum 하여 final output E를 얻습니다.
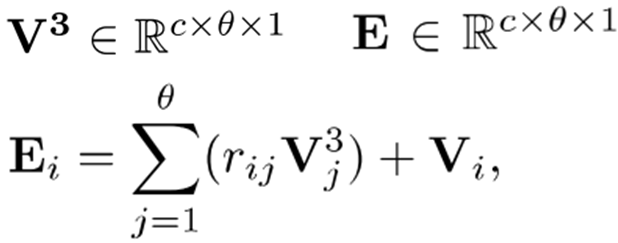
결과 feature E의 각 element는 모든 element와 원래 original feature의 weighted sum인 것을 알 수 있고, 마지막으로 각 local scope의 dependency features는 다음과 같이 표현할 수 있습니다.

Experiment
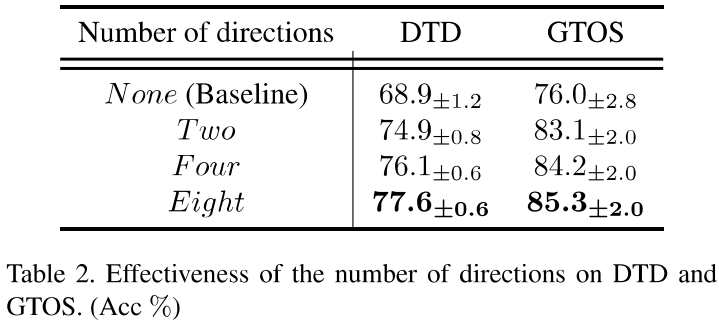
- Ablation study


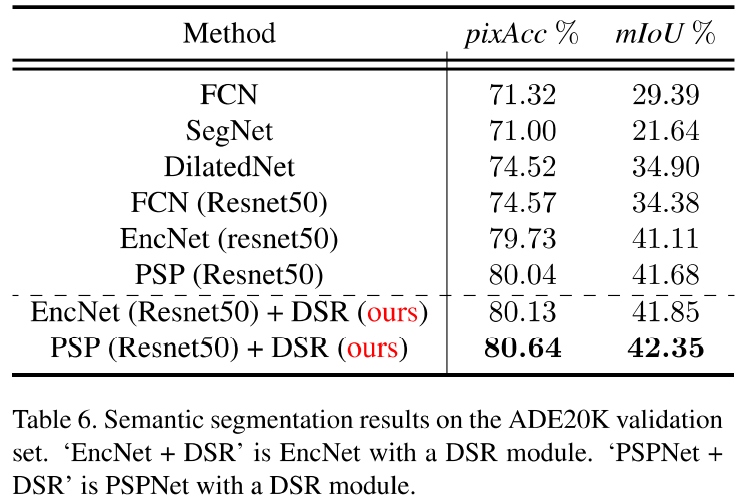
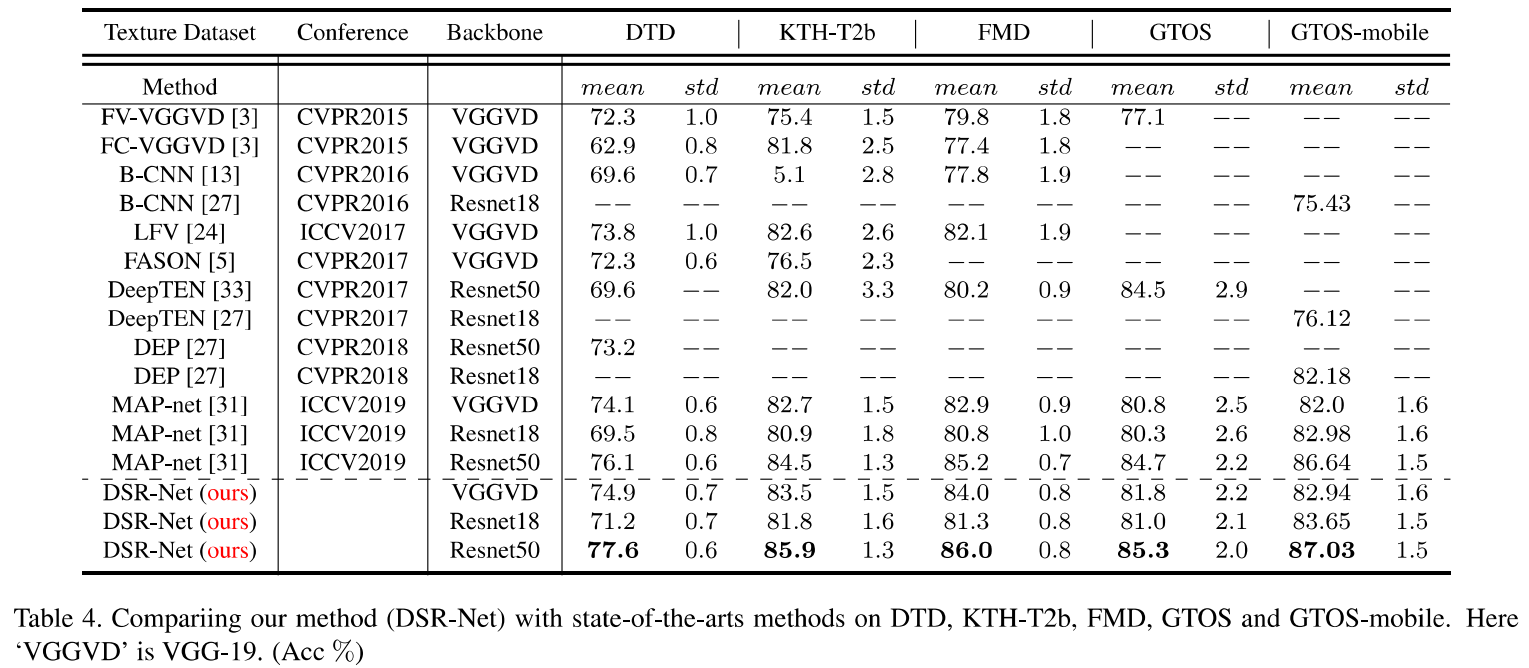
- Main Experiment
- Application : Fine-grained recognition, semantic segmentation