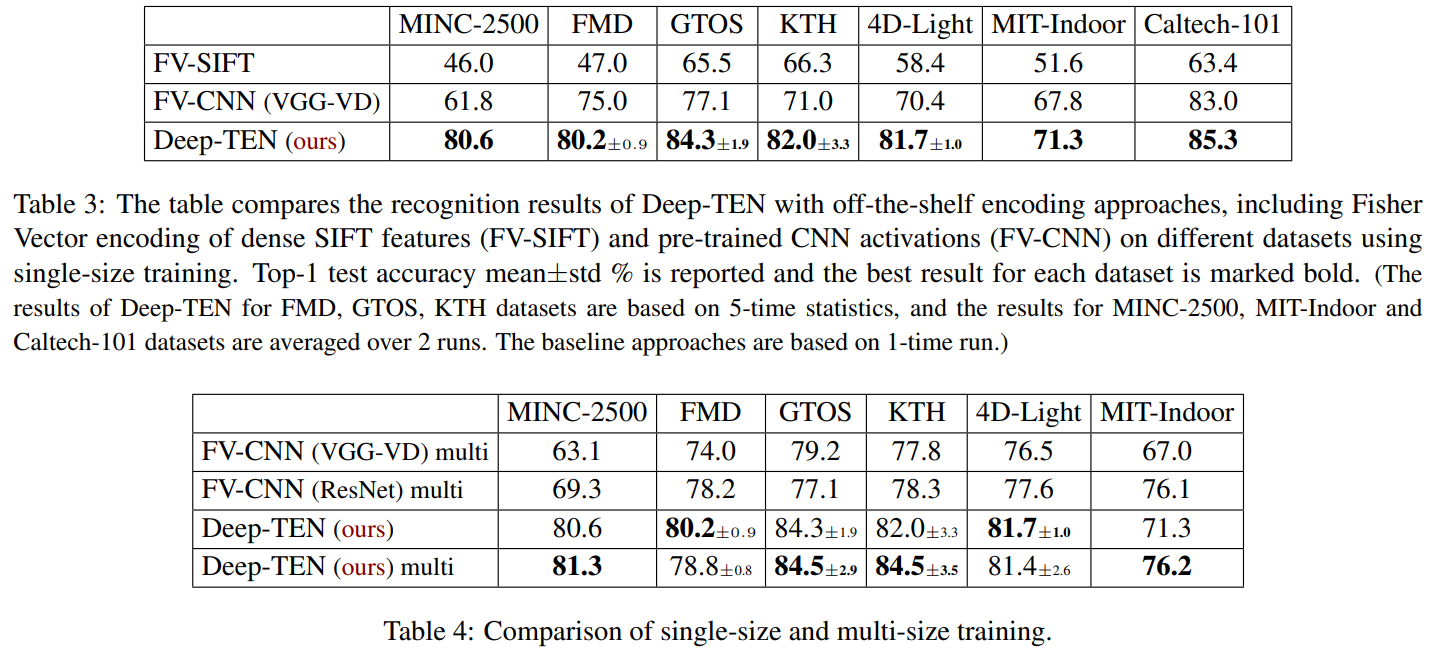
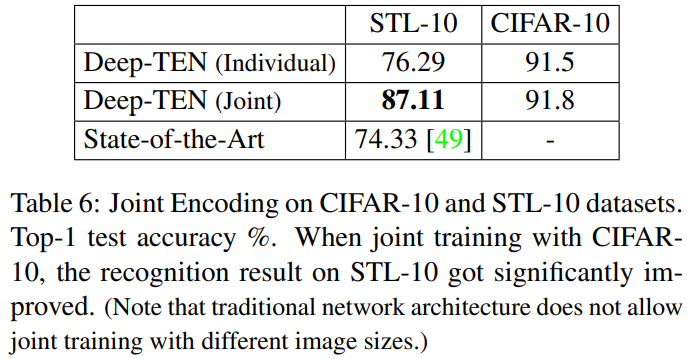
CVPR 2017에 게재된 본 논문은 classic한 computer vision approach인 dictionary learning 방법을 CNN 구조와 통합하여 end-to-end 로 material, texture 이미지의 orderless representation을 학습하는 DeepTEN 을 제안합니다.
Abstract
본 논문에서는 dictionary learning 및 encoding 파이프라인을 single model로 포팅하는 encoding layer가 있는 Deep Texture Encoding Network(Deep TEN)을 제안합니다. 이전 method에서는 SIFT descriptor 또는 material recognition으로 pre-trained CNN feature와 같은 별도의 standard encoder를 사용하여 개별적인 구성 요소로부터 만들어집니다. DeepTEN은 고유한 시각적 vocabulary들이 loss function에서 직접 학습되는 end-to-end 프레임워크입니다. classifier에 대한 feature, dictionary, encoding representation은 모두 동시에 학습됩니다. Representation은 orderless하므로 material 및 texture 인식에 특히 유용합니다. Encoding layer는 VLAS 및 Fisher vector와 같은 residual encoder를 generalize 하고 학습된 convolutional feature를 더 쉽게 transfer할 수 있도록 하는 domain specific information을 버리는 속성을 가지고 있습니다.
Introduction
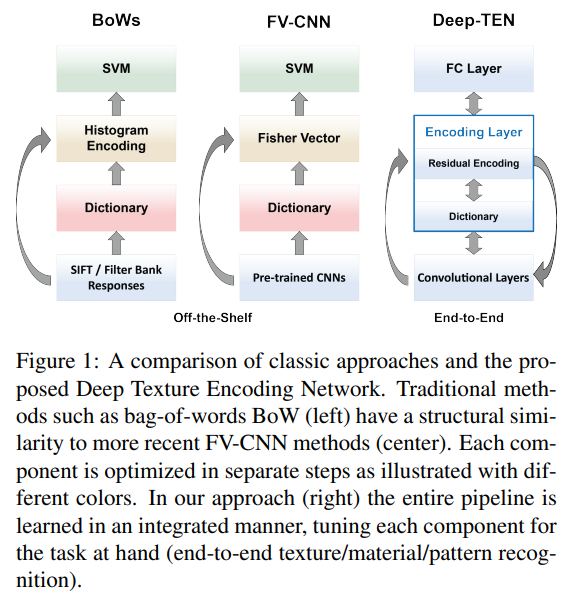
material 및 texture 인식 알고리즘의 목표는 object 인식과 유사하지만 일부 공간 반복을 포함하는 orderless한 measure을 캡처해야하는 challenge가 있습니다. 예를 들어, feature의 distribution 또는 histogram은 인식을 위한 orderless한 encoding을 제공합니다. material/texture 인식을 위한 클래식한 방법으로는 SIFT 또는 filter bank response 같은 interest point detector를 사용하여 feature를 추출합니다. Dictionary는 일반적으로 오프라인으로 학습된 후 feature distribution이 Bag-of-Words(BoW)에 의해 encoding됩니다. 마지막 단계에서는 SVM과 같은 classifier가 학습됩니다. 최근 작업에서는 hand-engineered feature와 filter bank는 pre-trained CNN으로 대체되고, BoW는 VLAD 및 Fisher vector와 같은 residual encoder로 대체됩니다. 이러한 기존의 접근 방식은 low level feature가 일반적이기 때문에 임의의 입력 이미지 크기를 허용하고 다른 domain 간에 feature를 transfer할 때 문제가 없다는 장점이 있습니다. 그러나 이러한 방법은 위 그림에서 시각화된 것 처럼, 자체적으로 포함된 알고리즘 구성 요소(feature extraction, dictionary learning, encoding, classifier training)을 쌓는 것으로 구성됩니다. 결과적으로 feature와 encoder가 구축되면 fix되어버리기 때문에, feature training이 labeled data의 장점을 이용하지 못한다는 단점이 있습니다. 제안하는 DeepTEN은 end-to-end로 학습되기 때문에 위에서 언급한 단점을 커버합니다.(그림의 제일 오른쪽)
* 일반적인 vanilla CNN 구조가 texture를 인식하기 어려운 이유 ?
CNN의 convolution layer는 local feature extractor 역할을 하는 슬라이딩 윈도우 방식으로 작동합니다. output feature map은 input image의 상대적인 spatial arrangement를 유지합니다. 결과로 생성된 feature는 classifier 역할을 하는 FC layer에 입력되는데, 이러한 프레임워크는 image classification, object detection, scene understanding 및 기타 응용 task에서 성공적인 결과를 보여줍니다. 하지만, texture는 spatially invariant한 representation이 필요하기 때문에 일반적인 CNN 구조는 texture를 인식하는데 ideal하지 않습니다. 따라서, end-to-end 학습에는 orderless feature pooling layer가 필요합니다. 문제는 input과 layer parameter와 관련하여 loss function을 미분가능하도록 만드는 것입니다. 본 논문에서는 새로운 back propagation series를 유도하고, 이러한 방식으로 orderless representation을 위한 encoding은 deep learning 파이프라인에 통합될 수 있습니다.
설명을 덧붙이자면 CNN-FC layer 구조는 spatial arrangement 에 민감한 구조이기 때문에 공간적 가변이 생기면 output이 크게 변할 수 있습니다. 그런데 texture 이미지는 한 클래스가 어떤 고유의 global shape을 가지지 않고 큰 가변성을 가지는 경우가 많습니다. 때문에 spatial arrangement에 민감한 network는 texture 인식에 유용하지 않습니다.
Learnable Residual Encoding Layer
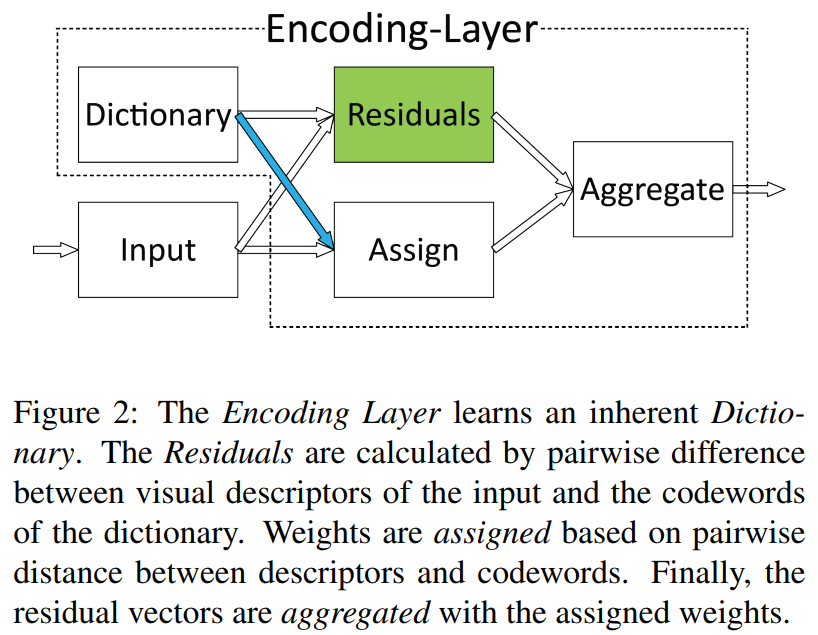

N개의 visual descriptor X(feature) 와 K개의 codeword로 구성된 codebook C가 있을 때, 각 descriptor xi와 cordword ck의 잔차로 residual vector rik(=xi-ck) 를 생성하고 wegith aik를 각 codeword ck에 할당할 수 있습니다. residual vector와 weight aik가 주어지면 residual encoding model은 모든 단일 codeword ck에 대해 아래과 같은 aggregation operatin을 수행하고 최종 encoder output E는 모든 K개의 codeword로 aggregation operation을 수행한 결과입니다.
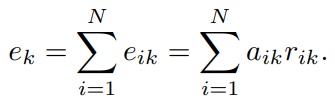
codeword에 descriptor를 할당하기 위한 assigning weight aik가 필요한데, Hard-assignment는 가장 가까운 codeword에 해당하는 각 descriptor xi에 0이 아닌 단일 weight를 제공합니다. Hard-assignment는 codeword의 모호성을 고려하지 않고, 미분이 불가능합니다. Soft-weight assingment는 각 codeword에 descirptor 를 할당하여 이를 해결합니다. 아래 첫 번째 식이 assigning weight이고 베타는 smoothing factor입니다. 본 논문에서는 gaussian mixture model(GMM)에서 영감을 받아 각 클러스터 중심 ck에 대한 smoothing factor sk 학습가능하도록 합니다(우측 식).
Encoding layer는 aggregate된 residual vector를 weight를 할당하여 concat합니다.
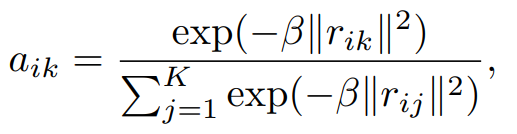

정리하면, residual vector rik 는 i번째 특정 feature와 k번째 특정 codeword의 차이 값이고, aissigning weight 는 residual vector를 embedding 해주기 위한 weight인데 softmax 함수 처럼 residual 값이 작은(feature와 가까운 cordword) 경우에 더 크게 activate 시키는 역할인 것 같습니다.
i번째 descriptor, k번째 codewor의 residual vector rik와 assigning weight aik 의 곱으로 eik 가 만들어지고, 모든 N개의 descriptor의 값을 합쳐 ek 가 생성됩니다. 그리고 모든 K개의 codeword에서 이전 연산을 수행하여 encoder output E가 만들어집니다. 즉, 최종 output 은 descriptor(feature)와 모든 codeword 들과의 correlation이 담겨있는 고정된 길이(cord는 spatial한 order가 없고 / cord의 개수를 지정하므로 -> code 개수에 따른 distribution 생성)의 orderless한 feature입니다.
이러한 encoding layer의 모든 구성 요소(입력 X, cordword, smoothing factor)들은 미분가능하기 때문에 back propagation과 standard SGD에 의해 end-to-end로 학습될 수 있습니다.
Experimental Results