반응형
딥러닝 모델은 대규모 데이터셋과 복잡한 신경망 구조를 사용하여 높은 예측 성능을 달성할 수 있다. 하지만 모델이 학습 데이터에 지나치게 맞춰져서 새로운 데이터에 대한 일반화 능력이 떨어지는 '과적합(overfitting)' 문제가 발생할 수 있는데. 이를 방지하고 모델의 일반화 성능을 향상시키기 위해 '정규화(regularization)' 기법이 사용된다.
Regularization (정규화)란 무엇인가?
정규화는 모델의 복잡성을 제어하여 과적합을 방지하고 일반화 성능을 향상시키는 기법이다. 이는 모델의 학습 과정에서 특정 제약 조건을 추가함으로써 이루어 지는데, 이러한 제약 조건은 모델이 지나치게 학습 데이터에 맞추지 않도록 하여 새로운 데이터에 대해 더 잘 일반화할 수 있도록 한다.
대표적으로 아래와 같은 방법들이 있다.
- Weight Decay - L1, L2
- Batch Normalization
- Early Stopping
Weight Decay

- Neural network의 특정 weight가 너무 커지는 것은 모델의 일반화 성능을 떨어뜨려 overfitting 되게 하므로, weight에 규제를 걸어주는 것이 필요.
- L1 regularization, L2 regularization 모두 기존 Loss function에 weight의 크기를 포함하여 weight의 크기가 작아지는 방향으로 학습하도록 규제
L1 Regularization vs L2 Regularization
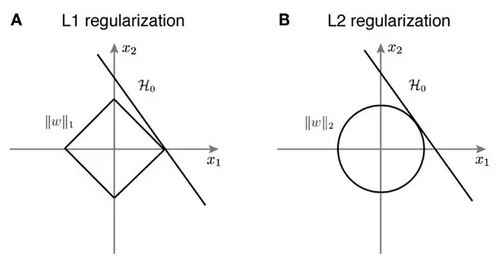
- L1 Regularization : weight 업데이트 시 weight의 크기에 관계없이 상수값을 빼게 되므로(loss function 미분하면 확인 가능) 작은 weight 들은 0으로 수렴하고, 몇몇 중요한 weight 들만 남음. 몇 개의 의미있는 값을 산출하고 싶은 sparse model 같은 경우에 L1 Regularization이 효과적. 다만 아래 그림에서 보듯이 미분 불가능한 지점이 있기 때문에 gradient-base learning 에서는 주의가 필요.
- L2 Regularization : weight 업데이트 시 weight의 크기가 직접적인 영향을 끼쳐 weight decay에 더욱 효과적
Batch Normalization

- Gradient vanishing/exploding 을 방지하기 위해 학습 과정 자체를 안정화시키기 위한 방법
- 학습시 네트워크의 각 layer 또는 activation 마다 입력 값의 분포가 달라지는 "Internal Covariance Shift" 가 발생하고 이를 해결하기 위해 입력값의 분포를 조정
- 평균과 분산을 조정하는 과정이 neural network 내부에 포함되어 학습시 batch의 평균과 분산을 이용하여 정규화
- scale과 shift(bias)를 감마, 베타 값으로 조정
- Inference 시에는 배치 단위의 평균과 분산을 구할 수 없기 때문에 학습 단계에서 moving average 또는 exponential average를 이용하여 계산한 평균과 분산을 고정값으로 사용
Batch Normalization 효과
- Gradient vanishing/exploding 을 완화하므로 높은 learning rate 사용하여 학습 속도 향상
- Careful weight initialization으로 부터 자유로워짐
- Regularization 효과 : BN 과정으로 평균과 분산이 지속적으로 변하고 weight 업데이트에도 영향을 주어 하나의 weight 가 매우 커지는 것을 방지.
Batch Normalization 주의 사항
- Batch size 가 너무 크거나 작으면 효과를 기대하기 어려움
- 사용 순서 : Convolution - BN - Activation - Pooling - ... (BN의 목적이 네트워크 연산 결과가 원하는 방향의 분포대로 나오게 하는 것이므로 conv 연산 바로 뒤에 주로 사용/ 아닌 경우도 있습니다.)
- Multi GPU training 시 주로 "Synchronized Batch Normalization" 사용
Early Stopping
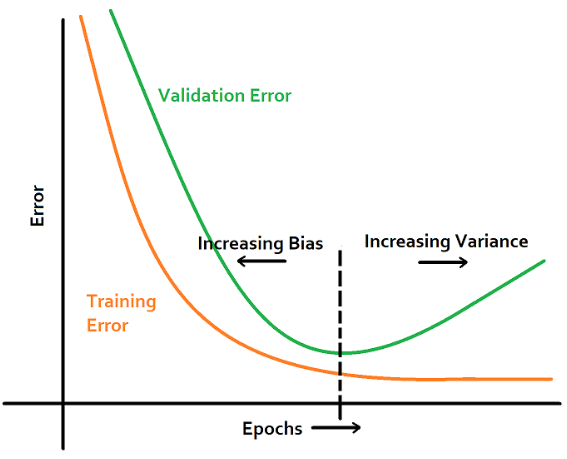
- 검증 손실(validation loss)이 더 이상 감소하지 않을 때 학습을 중지하는 기법
- Deep Neural Network는 일반적으로 학습을 너무 많이하면 특정 epoch 이후에는 overftting이 발생하여 test 성능 하락
- 이를 방지하기 위해 validation set을 이용하는 등의 방법으로 overfitting이 발생하기 전에 학습을 종료
반응형
'📖 Fundamentals > AI & ML' 카테고리의 다른 글
| [AI/ML] Precision, Recall, AP (Average Precision) 간단 설명 | 객체 검출 성능 지표 (1) | 2023.12.08 |
|---|---|
| [AI/ML] CNN에서 Convolutional layer의 개념과 의미 | 컨볼루션 신경망 | 합성곱 신경망 (3) | 2023.03.23 |
| [AI/ML] Cross Entropy( + Loss) & MSE Loss 설명 (0) | 2022.03.23 |
| [AI/ML] Classification과 Regression의 차이 (0) | 2022.03.23 |
| [AI/ML] Classification 성능 평가 방법 (0) | 2022.03.23 |