[튜토리얼] 누구나 사용할 수 있는 CLIP & KoCLIP 모델 예제 | 코딩 못해도 가능해! | 멀티모달 AI 예제 | CLIP & 한국어 CLIP
·
💻 Programming/AI & ML
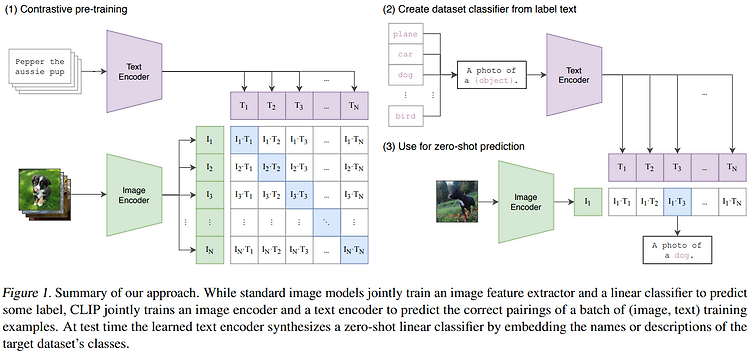
안녕하세요. 오늘은 기본적인 멀티모달 AI 모델인, CLIP을 사용해 보는 튜토리얼을 가져왔어요!사실 요즘은 딥러닝 프레임워크가 발전해서 굉장히 손쉽게 AI 모델을 다뤄볼 수 있는데요. CLIP 과 같은 트랜스포머 기반의 모델도 허깅페이스 API를 사용하면 굉장히 쉽게 사용해 볼 수 있어요. 특히 학습하지 않고 pre-trained(사전 학습된) 모델을 사용한다면 더더욱 쉽겠죠? *CLIP : Contrastive Language-Image Pretraining 그래서 오늘은 코딩을 할 줄 모르는 비개발자도 손쉽게 따라할 수 있는 튜토리얼을 만들어 왔답니다 ~~ 🤗사실 코드가 짧아서 뭐 만들었다고 할 수 있는 수준도 아니긴 해요 ㅎㅎCLIP Model 그래도 간단하게 라도 CLIP 모델이 무엇인지는 ..